





NVIDIA rende disponibile la versione 5 della piattaforma CUDA

NVIDIA aggiorna la propria piattaforma di sviluppo per il calcolo parallelo, estendendo la flessibilitą di utilizzo delle proprie GPU per ambiti di utilizzo che non siano quelli legati al tradizionale ambiente dei videogiochi
di Paolo Corsini pubblicata il 15 Ottobre 2012, alle 16:43 nel canale Private CloudNVIDIACUDA
NVIDIA ha annunciato la versione 5 della propria piattaforma CUDA per il calcolo parallelo utilizzzando le GPU delle famiglie GeForce, Quadro e Tesla; il download č accessibile gratuitamente da questo indirizzo in versioni a 32bit e a 64bit per i sistemi operativi Windows 8, 7 e Vista, Windows XP, Max OS X oltre che per differenti distribuzioni Linux.
La nuova release di CUDA implementa varie novitą che facilitano e arricchiscono il lavoro di programmazione per poter sfruttare la potenza di calcolo della GPU per ambiti di elaborazione non grafici:
- Parallelismo dinamico
I GPU threads possono dinamicamente produrre nuovi thread, consentendo alla GPU di adattarsi ai dati. Riducendo al massimo l'interscambio di dati e la comunicazione con la CPU, il parallelismo dinamico semplifica sensibilmente la programmazione parallela. Tra i benefici implementati permette l'accelerazione via GPU di un'ampia serie di algoritmi diffusi, come quelli utilizzati per l'adaptive mesh refinement e le applicazioni computazionali per la fluido dinamica. - GPU-Callable Libraries
Una nuova libreria CUDA BLAS consente agli sviluppatori di utilizzare il parallelismo dinamico per le loro GPU-callable Libraries. I prgrammatori possono quindi progettare plug-in API che permettono ad altri sviluppatori di estendere le funzionalitą dei loro kernel e implementare callback sulla GPU per personalizzare le funzionalitą delle GPU-callable Libraries di terze parti. La capacitą di “object linking” offre un processo efficiente per lo sviluppo di applicazioni su GPU, consentendo agli sviluppatori di compilare file sorgenti CUDA multipli in object file separati e unirli in applicazioni pił grandi e a librerie.
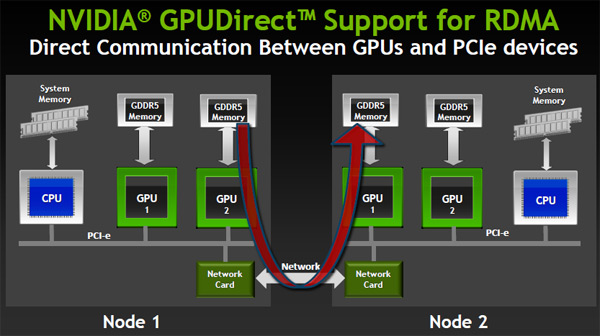
- Supporto GPUDirect per RDMA
La tecnologia GPUDirect permette la comunicazione diretta tra GPU e altri dispositivi PCI-E presenti nel sistema; supporta l'accesso diretto alla memoria tra la GPU e le schede di rete. Riduce significativamente anche la latenza MPISendRecv tra i nodi GPU in un cluster e migliora le performance complessive. Questa funzionalitą si rivela particolarmente utile nel momento in cui, come spesso capita in datacenter, le GPU sono montate in sistemi differenti collegati tra di loro attraverso connessione ethernet tradizionale. - NVIDIA Nsight Eclipse Edition
NVIDIA Nsight Eclipse Edition consente ai programmatori di sviluppare, effettuare il debug e profilare le applicazioni GPU nell'ambito Eclipse-based IDE su piattaforma Linux e Mac OS X. Un editor e sample CUDA integrati velocizzano la generazione di codice CUDA e il refactoring automatico di codice consente di fare il porting facilmente su kernel CUDA. Un sistema integrato offre analisi delle performance automatiche e guida passo-passo per rimediare ai colli di bottiglia nel codice, mentre l'evidenziazione della sintassi rende pił semplice differenziare il codice GPU da quello CPU.
 Lenovo ThinkVision 3D 27, la steroscopia senza occhialini
Lenovo ThinkVision 3D 27, la steroscopia senza occhialini  La Formula E può correre su un tracciato vero? Reportage da Misano con Jaguar TCS Racing
La Formula E può correre su un tracciato vero? Reportage da Misano con Jaguar TCS Racing Lenovo LEGION e LOQ: due notebook diversi, stessa anima gaming
Lenovo LEGION e LOQ: due notebook diversi, stessa anima gaming AGCM apre istruttoria su Enel: presunte irregolarità nella comunicazione dei rinnovi
AGCM apre istruttoria su Enel: presunte irregolarità nella comunicazione dei rinnovi Cuffie Sennheiser MOMENTUM 4 Wireless: qualitą audio ad altissimi livelli e cancellazione adattiva del rumore, oggi in offerta a 256€
Cuffie Sennheiser MOMENTUM 4 Wireless: qualitą audio ad altissimi livelli e cancellazione adattiva del rumore, oggi in offerta a 256€ SSD 1080 PRO non è quello che pensate: si spaccia per SSD Samsung, ma è un falso
SSD 1080 PRO non è quello che pensate: si spaccia per SSD Samsung, ma è un falso Ring Intercom ed Echo Pop: sconto imperdibile per l'accoppiata smart per la casa
Ring Intercom ed Echo Pop: sconto imperdibile per l'accoppiata smart per la casa ASML, intesa con il governo olandese: piano d'espansione a nord di Eindhoven
ASML, intesa con il governo olandese: piano d'espansione a nord di Eindhoven Portatile Low cost potentissimo: AMD Ryzen 7 5700U (8C/16T a 4,3GHz), 16GB RAM, SSD 512GB, Full HD e costa 469€ per utenti Prime!
Portatile Low cost potentissimo: AMD Ryzen 7 5700U (8C/16T a 4,3GHz), 16GB RAM, SSD 512GB, Full HD e costa 469€ per utenti Prime! I nuovi coupon nascosti di Amazon: ecco come risparmiare (anche tanto) su moltissimi prodotti in offerta (aprile 2024)
I nuovi coupon nascosti di Amazon: ecco come risparmiare (anche tanto) su moltissimi prodotti in offerta (aprile 2024) Torna il super tablet da 109€ con display 10.1" Full HD, 8GB/256GB, LTE e batteria da 8580mAh!
Torna il super tablet da 109€ con display 10.1" Full HD, 8GB/256GB, LTE e batteria da 8580mAh! Meta copia Microsoft con Windows: il sistema operativo dei Quest a produttori di terze parti. Arriva il 'visore Xbox'
Meta copia Microsoft con Windows: il sistema operativo dei Quest a produttori di terze parti. Arriva il 'visore Xbox' Blackmagic Design: arriva il nuovo software di video editing DaVinci Resolve 19
Blackmagic Design: arriva il nuovo software di video editing DaVinci Resolve 19 La sonda spaziale NASA Voyager 1 ricomincia a inviare dati ingegneristici utilizzabili
La sonda spaziale NASA Voyager 1 ricomincia a inviare dati ingegneristici utilizzabili Blackmagic PYXIS 6K per riprendere filmati di alta qualità fino a 6K
Blackmagic PYXIS 6K per riprendere filmati di alta qualità fino a 6K Sapphire Nitro+ B650I Wi-Fi: un’ottima scheda madre che forse non vedremo mai in Europa
Sapphire Nitro+ B650I Wi-Fi: un’ottima scheda madre che forse non vedremo mai in Europa













_XXL.jpg)













0 Commenti
Gli autori dei commenti, e non la redazione, sono responsabili dei contenuti da loro inseriti - infoDevi effettuare il login per poter commentare
Se non sei ancora registrato, puoi farlo attraverso questo form.
Se sei già registrato e loggato nel sito, puoi inserire il tuo commento.
Si tenga presente quanto letto nel regolamento, nel rispetto del "quieto vivere".