






Il sistema di opt out per l'IA di Meta non funziona. Secondo alcuni sviluppatori è una pura mossa di marketing
di Alberto Falchi pubblicata il 30 Ottobre 2023, alle 16:41 nel canale data
Meta ha introdotto uno strumento per rimuovere specifici contenuti dai dati usati per addestrare la sua IA. Il problema è che non funziona come dovrebbe. Anzi: non è nemmeno un modulo per l'opt out, quanto uno strumento per segnalare violazioni del GDPR
I sistemi di intelligenza artificiale generativa hanno un "difetto": vengono spesso addestrati su dati liberamente disponibili in rete, come articoli di giornale, post sui blog, interventi su Reddit o sui social network e via dicendo. Questo ha inevitabilmente sollevato più di un dubbio sugli aspetti relativi al copyright, tanto che le varie piattaforme hanno velocemente introdotto dei sistemi di opt-out che consentono alle aziende di evitare lo scraping dei propri dati, evitando così che vengano utilizzati per il training dei modelli di IA. Molte grandi testate, fra cui il New York Times, hanno deciso di non volere che i propri articoli vengano utilizzati da OpenAI o altre realtà.
Non è solo OpenAI che ha introdotto delle opzioni per l'opt out: anche altre imprese hanno seguito questo esempio, fra cui Meta: compilando il modulo presente a questo indirizzo, si potrà evitare di addestrare il LLM dell'azienda con le proprie informazioni. C'è però un problema: sembra che non funzioni.
Meta e privacy: un problema senza fine
Come riporta Wired, numerosi sviluppatori stanno lamentando seri problemi con lo strumento offerto da Meta per evitare di addestrare l'IA tramite i propri contenuti. Il motivo è che chi ha fatto la richiesta si è visto rispondere con una mail che indica l'impossibilità di procedere: per poter eseguire l'operazione richiesta, infatti, è necessario fornire prove del fatto che le informazioni personali appaiano in una risposta dell'IA generativa di Meta.
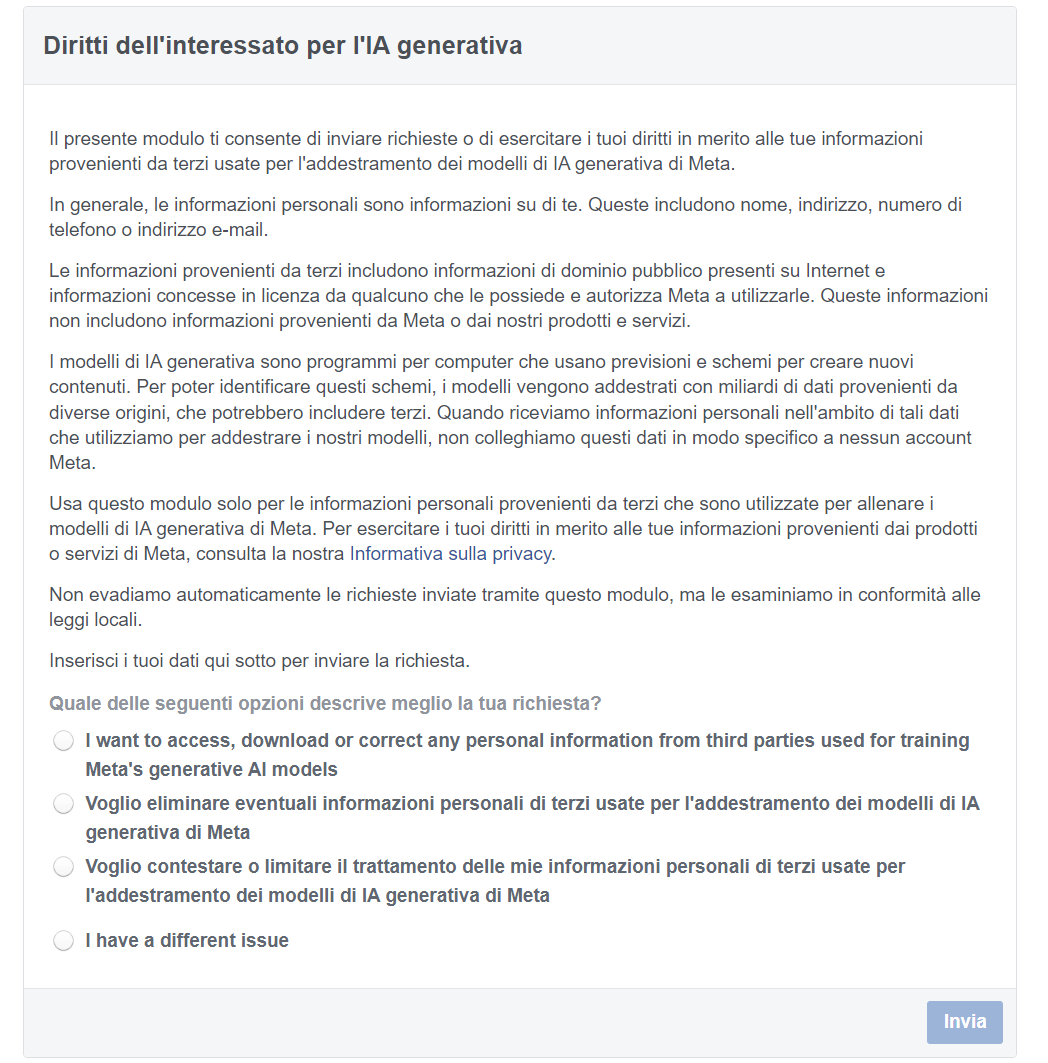
In pratica, al contrario di altri sistemi di IA che automaticamente eliminano dal proprio modello le informazioni personali degli utenti che ne fanno richiesta, Meta pretende una prova che queste informazioni siano realmente state utilizzate. La prova, in questo caso, è portare all'attenzione dell'azienda guidata da Zuckerberg un prompt che dia come output le informazioni personali che si vogliono eliminare, siano esse immagini o contenuti testuali. Solo in questo caso procederà con la rimozione.
La testata americana riporta il commento di Bethany Berg, artista del Colorado: "Ho cominciato a sentire che fosse solo una finta operazione di pubbliche relazioni [PR stunt, nell'originale] per far sembrare che stessero effettivamente cercando di fare qualcosa", spiega Berg. Che non è l'unica persona a sentirsi presa in giro.
La risposta ufficiale di Meta è che c'è stato un fraintendimento: il form presente sul sito di Meta non è da considerarsi come un modulo di opt out. "Penso che ci sia un po' di confusione su cosa sia quel modulo e sui controlli che offriamo," scrive Thomas Richards, portavoce di Meta, in una email inviata a Wired. "Attualmente non offriamo una funzione che permetta alle persone di scegliere di non consentire che le loro informazioni dai nostri prodotti e servizi vengano utilizzate per addestrare i nostri modelli di intelligenza artificiale. Per fornire un po' più di contesto riguardo al modulo di richiesta, a seconda di dove vivono le persone, potrebbero essere in grado di esercitare i loro diritti di soggetto dei dati e opporsi all'uso di alcune informazioni di terze parti per addestrare i nostri modelli di intelligenza artificiale, afferma Richards. "La presentazione di una richiesta non significa che le informazioni di terze parti saranno automaticamente rimosse dai nostri modelli di addestramento dell'IA. Stiamo esaminando le richieste in conformità con le leggi locali, poiché diverse giurisdizioni hanno requisiti diversi. Non ho ulteriori dettagli sul processo".
In pratica, lo strumento di Meta serve solamente per segnalare eventuali violazioni di norme come, per esempio, il GDPR. Ma anche in questo caso, non sembra banale riuscire a dimostrare la cosa e far rimuovere le informazioni dal sistema. Al momento sembra quindi non esserci uno strumento per impedire a Meta di addestrare l'IA sui propri contenuti. Un approccio che ci lascia più di una perplessità, anche sotto il profilo della legalità.



 Recensione Samsung Galaxy Z Fold7: un grande salto generazionale
Recensione Samsung Galaxy Z Fold7: un grande salto generazionale  The Edge of Fate è Destiny 2.5. E questo è un problema
The Edge of Fate è Destiny 2.5. E questo è un problema Ryzen Threadripper 9980X e 9970X alla prova: AMD Zen 5 al massimo livello
Ryzen Threadripper 9980X e 9970X alla prova: AMD Zen 5 al massimo livello Identikit della scheda video perfetta, pensieri tra il serio e il faceto
Identikit della scheda video perfetta, pensieri tra il serio e il faceto SUV, 100% elettrico e costa meno di un benzina: Leapmotor B10 disponibile in Italia
SUV, 100% elettrico e costa meno di un benzina: Leapmotor B10 disponibile in Italia Hai mai caricato un referto su ChatGPT? Hai messo in grave pericolo la tua salute e la tua privacy
Hai mai caricato un referto su ChatGPT? Hai messo in grave pericolo la tua salute e la tua privacy















3 Commenti
Gli autori dei commenti, e non la redazione, sono responsabili dei contenuti da loro inseriti - infoA giudicare dalla qualità dei contenuti generati con l'IA, penso proprio di sì. Contenuti che poi vengono ripostati su FB stesso. È un ciclo autoalimentato.
Comunque ho appena letto che sembrerebbe che le "Meta-learning for Compositionality" (MLC)
e anche se dal nome Meta dell'articolo non centra nulla, siano superiori alle AI soprattutto per parlare e comprendere le parole piu' simili a Noi, bah vedremo, per ste cose siamo nella Preistoria purtroppo o per fortuna..
Devi effettuare il login per poter commentare
Se non sei ancora registrato, puoi farlo attraverso questo form.
Se sei già registrato e loggato nel sito, puoi inserire il tuo commento.
Si tenga presente quanto letto nel regolamento, nel rispetto del "quieto vivere".