






Intel Experience Day 2022: dal supercomputer Leonardo al Federated learning, l'IA rispettosa della privacy
di Alberto Falchi , Vittorio Manti pubblicata il 20 Dicembre 2022, alle 09:51 nel canale data
L'appuntamento annuale dell'Intel Experience Day, che quest'anno è tornato in presenza, è stata l'occasione per l'azienda guidata da Pat Gelsinger per delineare alcuni passaggi importanti della sua strategia e per sottolineare come le attività vanno ben oltre la produzione di microprocessori.
Il primo tema affrontato da Andrea Toigo, EMEA Territory Sales Manager di Intel, ci riguarda da vicino. Si parla, già da tempo, di uno stabilimento Intel in Italia, tassello di una più ampia strategia che, nelle intenzioni di Intel, porterà a spostare nel territorio dell’Unione Europea il 20% della produzione di semiconduttori. Semiconduttori che comunque rimangono al centro delle attività di Intel e il cui sviluppo tecnologico ha reso obsoleto il modo in cui è stato “misurato” fino a oggi il processo produttivo. Siamo stati abituati per decenni a valutare la dimensione del gate dei transistor all’interno di un microprocessore come elemento base per avere un’idea di come si è evoluto il processo produttivo. L’evoluzione della tecnologia, però, ha reso questa misura non più significativa e quindi con i processori Intel Core di 12ma e 13ma generazione si è passati a una nuova notazione.

Oggi sono quindi sul mercato processori con processo produttivo denominato Intel 7 e da qui al 2024 vedremo arrivare Intel 4, Intel 3 e Intel 20A. Intel è convinta che le innovazioni tecnologiche di queste nuove generazioni di processori permetteranno di mantenere viva la famosa Legge di Moore, secondo la quale il numero di transistor presenti all’interno di un microprocessore (a parità di dimensione del die, ndr) raddoppia ogni due anni. Seguendo questo trend, Intel prevede di avere 10.000 miliardi di transistor in un singolo chip nei prossimi anni.
Il supercomupter Leonardo di Cineca è il quarto più potente al mondo
Oltre a trasferire la produzione dei semiconduttori in Europa, un altro trend in atto è quello che vede l’Unione Europa attiva nel potenziare l’infrastruttura IT del continente. In quest’ottica è molto significativo quanto raggiunto da Cineca con il supercomputer Leonardo. È di pochi giorni fa la notizia che Leonardo si è classificato quarto al mondo nella classifica dei supercomputer con maggiore capacità elaborativa, con 240 petflops raggiunti tramite all’ingegnerizzazione, tutta italiana, del sistema dotato di 3.456 nodi, ognuno dei quali basato su CPU Intel Xeon con 32 core. Durante l’evento di Intel, abbiamo avuto l’occasione di intervistare Claudio Arlandini, Project Manager HPC Department di Cineca, al quale abbiamo chiesto qual è il modello di accesso alla capacità elaborativa di Leonardo e se potrà essere sfruttata sia da enti di ricerca che da aziende.

Claudio Arlandini ha risposto: “In Cineca sono responsabile di un team che si occupa specificatamente di progetti per l’industria e abbiamo delle collaborazioni con tantissime imprese, non solo quelle grandi come ENI, ma anche con tantissime piccole e medie imprese. Oggi c’è un forte interesse per Leonardo, ma in Cineca abbiamo una serie di super calcolatori. Il presupposto è che l’iniziativa EuroHPC stabilisce che almeno il 10% delle ore di calcolo devono essere in qualche modo dedicate all’industria. C’è quindi una forte spinta da parte della Comunità Europe all’utilizzo di questi sistemi di calcolo e ci saranno sicuramente delle call di accesso riservate all’industria. Ritengo particolarmente importante rendere accessibile tutta l’infrastruttura dell’ecosistema, all’interno della quale si inserisce Leonardo. In questo contesto è nato il centro di competenza nazionale, che ha l’obiettivo di mettere l’industria al centro di una serie di iniziative che permettono di sfruttare Leonardo. Tema fondamentale è la creazione delle skill, anche attraverso percorsi di formazione, perché non è sufficiente andare a cercare le competenze altrove, ma devono essere costruite giorno per giorno all’interno delle aziende ed è per questo che con il mio gruppo abbiamo realizzato un tour itinerante che ha visto l’organizzazione di una ventina di eventi che hanno portato ad ascoltarci più di 700 persone provenienti da 180 aziende.”
Arlandini ha ribadito che, in ogni caso, l’accesso alle risorse di Cineca, e di Leonardo in particolare, avviene attraverso delle call in cui enti di ricerca e aziende presentano i loro progetti, che vengono valutati e se approvati vengono poi sviluppati utilizzando le risorse di Cineca.
Abbiamo poi chiesto ad Arlandini quali difficoltà progettuali si incontrano nel disegnare e implementare una architettura così complessa come quella di Leonardo.
Arlandini: “È stato un problema enorme, stiamo parlando di una macchina che ha un consumo nell’ordine di dieci megawatt, posizionato all’interno di una città come Bologna. Contemporaneamente a Leonardo, la Comunità Europea ha finanziato un’altra macchina, più o meno della stessa potenza, in Finlandia. Il grande vantaggio dei finlandesi è stato di posizionare il loro supercomputer oltre il circolo polare artico, vicino a una vecchia segheria, quindi risolvendo allo stesso tempo sia il problema del raffreddamento che dell’energia elettrica necessaria. Abbiamo dovuto rendere il datacenter il più sostenibile possibile, andando ad abbassare il cosiddetto PUE. Grazie ad Atos siamo riusciti a implementare un sistema di raffreddamento smart che non ha bisogno di cooler esterni, in quanto si usa acqua calda a 37 gradi che viene pompata direttamente sui processori, dove raggiunge i 45 gradi, raccolta con un sistema ricircolo che sposta l’acqua in un capannone affianco dove ci sono degli evaporatori passivi e poi rispedita abbassata al punto di partenza.”
Un altro tema molto significativo affrontato durante l’evento Intel Experience Day è legato all’applicazione dell’intelligenza artificiale al mondo sanitario.
L’IA sta aiutando ricercatori in vari ambiti a fare enormi passi avanti ma ci sono situazioni in cui l’utilizzo di queste tecnologie richiede particolari attenzioni. Come nel campo medico, dove è fondamentale che gli algoritmi vengano applicati mantenendo però il pieno rispetto della privacy dei pazienti. Intel, insieme alla Perelman School of Medicine della University of Pennsylvania ha sperimentato il federated learning, una tecnica cha fa leva sul machine learning distribuito.
Condividere le informazioni sanitarie grazie al federated learning
Condividere i dati medici è estremamente complicato a causa di leggi locali e nazionali che, giustamente, limitano la diffusione delle informazioni sanitarie, dati estremamente sensibili. Questo significa che i ricercatori sono costretti a utilizzare solo set di dati limitati, e non possono accedere a database più ampi. “Puoi avere a disposizione tutta la potenza di calcolo del mondo, ma non servirebbe a niente senza una quantità sufficiente di dati da analizzare”, spiega Rob Enderle, principal analyst, Enderle Group. “L’impossibilità di analizzare dati già raccolti ha rallentato significativamente i progressi che l’AI potrebbe rendere possibili in campo medico. Questo studio di federated learning mostra un percorso sostenibile per consentire all’AI di realizzare il proprio potenziale, diventando lo strumento più efficace contro le malattie più complesse”.
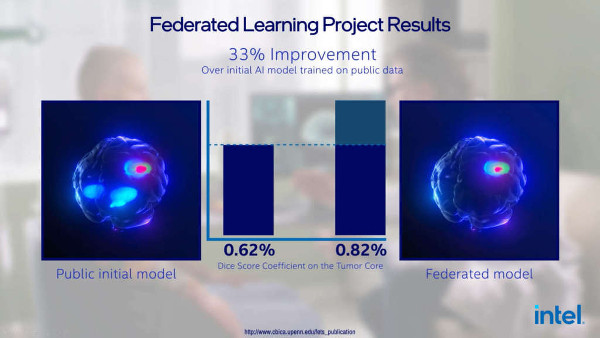
Il federated learning è una tecnica che permette di ovviare a queste limitazioni distribuendo i calcoli di machine learning si più sistemi e assicurando la totale privacy dei pazienti. La ricerca condotta da Intel e l’Università del Pennsylvania è il più grande studio di federated learning mai svolto, e ha sfruttato un dataset contenente informazioni provenienti da 71 organizzazioni mediche dislocate in cinque continenti. I risultati sono decisamente incoraggianti, e hanno dimostrato la possibilità di migliorare del 33% la capacità di rilevare i tumori al cervello.
“In questo studio, il federated learning mostra la sua capacità di spostare il paradigma della sicurezza della collaborazione tra diverse istituzioni, dando accedesso al più grande e diversificato dataset di pazienti affetti da glioblastoma mai analizzato, assicurando al contempo la salvaguardia dei dati, che rimangono sempre negli istituti che li hanno raccolti. Quanti più dati riusciamo a inserire nei modelli di machine learning, tanto più precisi questi diventano, migliorando la nostra capacità di comprendere ed elaborare terapie per affrontare anche patologie rare come il glioblastoma”, commenta Spyridon Bakas, PhD, assistente di patologia, medicina di laboratorio e radiologia presso la Perelman School of Medicine della University of Pennsylvania e autore senior della ricerca.
Come funziona il federated learning
Il federated learning distribuisce i calcoli di machine learning su differenti sistemi, permettendo ai ricercatori di collaborare garantendo la privacy dei dati sanitari. Il funzionamento è relativamente semplice da comprendere: ogni struttura sanitaria elabora i propri dati tramite un sistema di IA locale, separatamente. I dati usati per il training dell’IA vengono poi ricombinati per generare un modello globale, nel pieno rispetto della privacy.
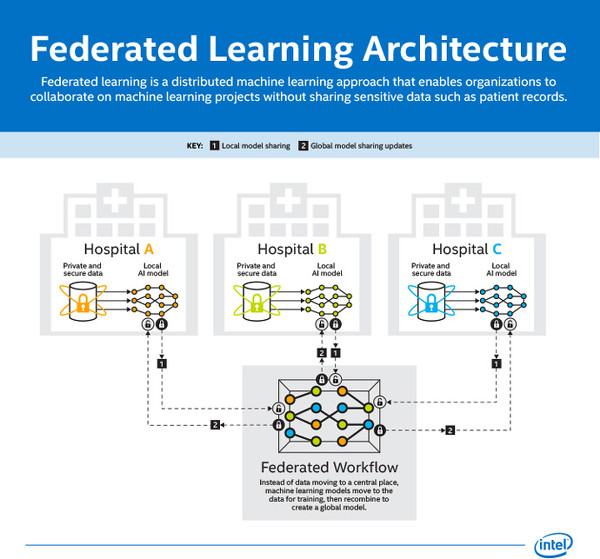
“Il federated learning ha un enorme potenziale in numerosi campi e in particolare in quello sanitario, come dimostra la nostra ricerca con Penn Medicine. La capacità di proteggere le informazioni e i dati sensibili apre la strada a studi e collaborazioni future, specialmente in quei casi in cui i dataset sarebbero altrimenti inaccessibili. Il nostro lavoro con Penn Medicine può avere ricadute positive sui pazienti di tutto il mondo e guardiamo con fiducia alla possibilità di continuare a esplorare le potenzialità del federated learning” ha dichiarato Jason Martin, principal engineer, Intel Labs



 Recensione Samsung Galaxy Z Fold7: un grande salto generazionale
Recensione Samsung Galaxy Z Fold7: un grande salto generazionale  The Edge of Fate è Destiny 2.5. E questo è un problema
The Edge of Fate è Destiny 2.5. E questo è un problema Ryzen Threadripper 9980X e 9970X alla prova: AMD Zen 5 al massimo livello
Ryzen Threadripper 9980X e 9970X alla prova: AMD Zen 5 al massimo livello Hai mai caricato un referto su ChatGPT? Hai messo in grave pericolo la tua salute e la tua privacy
Hai mai caricato un referto su ChatGPT? Hai messo in grave pericolo la tua salute e la tua privacy Apple vuole un nuovo campus nella Silicon Valley. Apple Park non basta più
Apple vuole un nuovo campus nella Silicon Valley. Apple Park non basta più DJI Osmo 360, la nuova action cam a 360° usa un sensore quadrato e registra in 8K
DJI Osmo 360, la nuova action cam a 360° usa un sensore quadrato e registra in 8K 















2 Commenti
Gli autori dei commenti, e non la redazione, sono responsabili dei contenuti da loro inseriti - infoServirebbe un poco più di rigore...
...nello scrivere articoli tecnologico-scientifici.A quali "gradi" ci si riferisce ad esempio !"
Gradi sessagesimali !
Gradi centigradi (voglio sperare di no).
Meglio "gradi Celsius" per non scomodare Lord Kelvin.
Tutto questo dovendo prescindere dal contesto da cui di desume che di scala termometrica si tratterebbe...ma vanno specificate le unità di misura.
Marco71
In quelle zone ci sta che dell'acqua (o meglio liquido) inizialmente a 45 gradi Celsius esposto praticamente all'aperto (evaporatore passivo, sarà tipo un radiatore ?) scenda a 37 in poco tempo !
Devi effettuare il login per poter commentare
Se non sei ancora registrato, puoi farlo attraverso questo form.
Se sei già registrato e loggato nel sito, puoi inserire il tuo commento.
Si tenga presente quanto letto nel regolamento, nel rispetto del "quieto vivere".