






Per IBM l'IA dev'essere aperta. Le novità presentate a THINK
di Vittorio Manti , Riccardo Robecchi pubblicata il 30 Maggio 2024, alle 17:41 nel canale Innovazione
L'intelligenza artificiale secondo IBM dev'essere aperta e "verificabile": per questo l'azienda ha reso open source i suoi modelli. Ed è anche l'unica ad avvisare che potrebbero esserci allucinazioni. Abbiamo incontrato alcuni rappresentanti dell'azienda a Milano
IBM ha presentato diverse novità durante la sua conferenza annuale, THINK. Grande importanza è stata data all'intelligenza artificiale, con un approccio che punta molto sull'apertura (sia perché i modelli sono open source, sia per via delle informazioni che vengono condivise su come sono stati addestrati) e sulla facilità d'integrazione nelle varie componenti dell'infrastruttura IT aziendale.
Per approfondire gli annunci di THINK, IBM ha organizzato un evento stampa a Milano, a cui Edge9 ha partecipato. All’evento erano presenti Stefano Rebattoni (a sinistra), Presidente e AD di IBM Italia, Tiziana Tornaghi (al centro), Managing Partner della divisione Consulting, e, ospite d’eccezione, Sebastian Krause(a destra), Senior Vice President e Chief Revenue Officer di IBM.

Rebattoni ha aperto l’evento riportando alcuni dei dati più significativi dell’IBM CEO Study, arrivato nel 2024 alla 29ma edizione. Dal report emerge in modo molto netto come oggi l’argomento principale di discussione sia l’intelligenza artificiale generativa, vista come motore di innovazione, elemento questo essenziale per poter competere sul mercato. Solo 12 mesi fa l’IA generativa non era menzionata e l’innovazione era vista come una delle sfide principali, ma quest’anno è balzata dal sesto al primo posto. Emerge anche come sia essenziale che l’IA generativa debba essere più affidabile e, vedremo, come questo è uno degli aspetti principali che sono influenzati dalle novità presentate a THINK.
Partiamo quindi da una carrellata degli annunci più significativi di THINK, per poi riportare quello che Sebastian Krause ci ha riferito in chiusura dell’evento.
L'IA secondo IBM è aperta
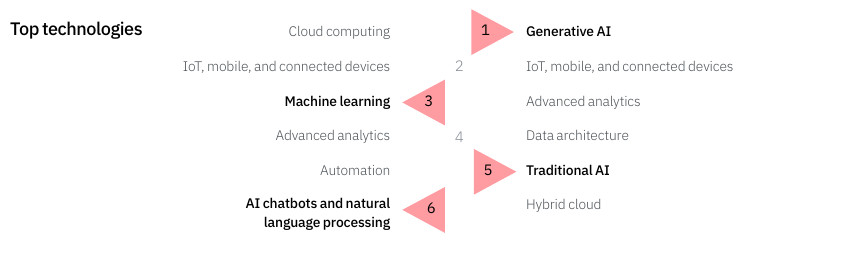
Come rivela lo studio CEO Study, l'IA ricopre un ruolo sempre più cruciale nei piani delle aziende. È (anche) per questo che i modelli linguistici IBM Granite su cui si basa l'offerta dell'azienda sono stati resi open source: un passo importante, che rende possibile il loro uso a chiunque grazie alla licenza Apache 2.0, una licenza molto permissiva che consente un uso pressoché senza limiti del codice e garantisce i diritti di sfruttamento di eventuali brevetti collegati.
I modelli Granite, che vanno da 3 a 34 miliardi di parametri, sono disponibili su Hugging Face e GitHub in diverse varianti, sia "base" sia specifiche per alcuni compiti come la generazione di codice la sua documentazione, la manutenzione di repository e altro ancora. L'addestramento è avvenuto su 116 linguaggi di programmazione, il che dà loro una buona flessibilità.
Secondo IBM, i benchmark condotti su Granite mostrano che hanno prestazioni spesso superiori rispetto ad altri modelli open source di dimensioni doppie. Una particolarità del modello base da 20 miliardi di parametri per il codice è che è in grado di generare codice SQL da domande in linguaggio naturale.
Un aspetto particolarmente interessante e importante è legato alla proprietà intellettuale: si parla moltissimo del fatto che molti modelli, uno su tutti ChatGPT, sono stati addestrati su dati presi da Internet senza alcun riguardo per la loro proprietà intellettuale, esponendo così chi ne utilizzasse i prodotti (siano essi testo, codice o altro) a possibili cause legali. IBM ha documentato rigorosamente il processo di addestramento e i dati usati per esso, con pubblicazioni scientifiche al riguardo che certificano l'origine dei dati. Data la sicurezza che l'azienda ha circa la liceità dell'uso dei dati, IBM ha inoltre deciso di indennizzare i clientiqualora questi riscontrassero problemi relativi alla proprietà intellettuale e al copyright a seguito dell'uso dei modelli.
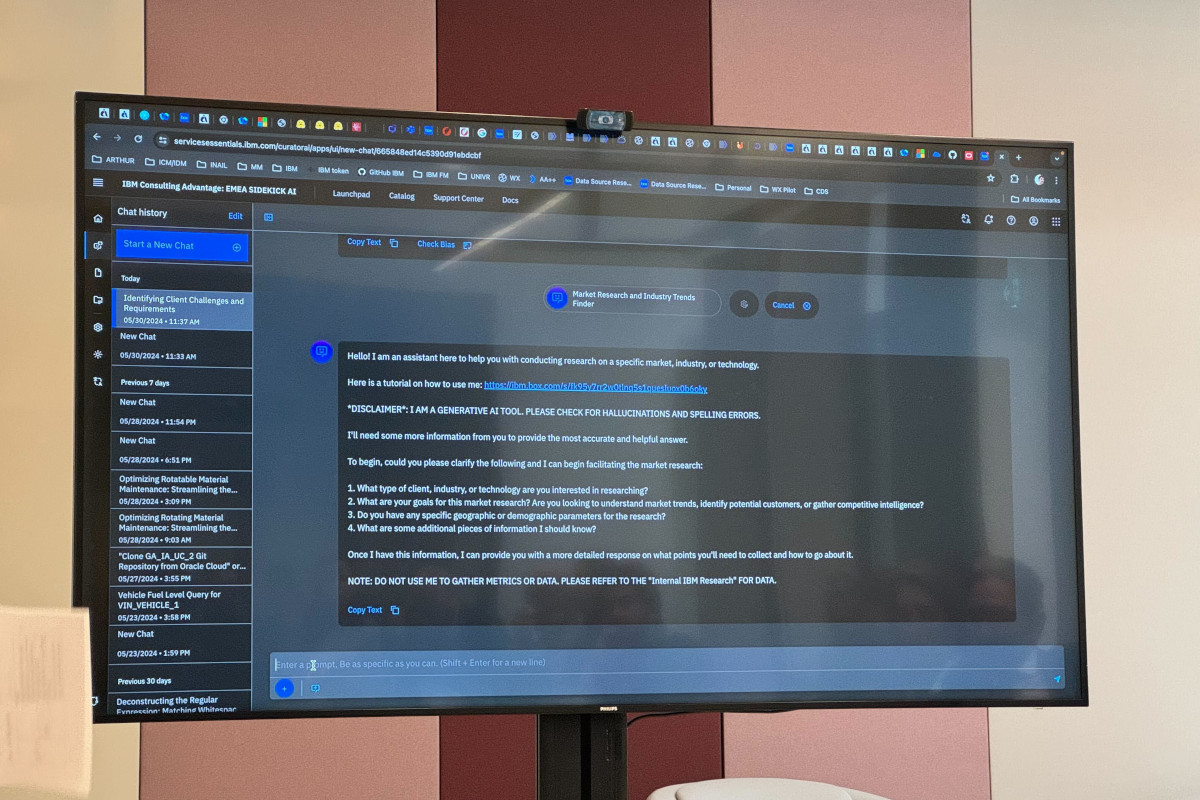
Un aspetto estremamente significativo, che va in qualche modo a confermare l'approccio cauto di IBM all'IA generativa, emerge da una schermata che è stata mostrata durante l'evento: l'assistente d'IA si presenta e include un avviso che dice "sono uno strumento d'IA generativa. Siete pregati di controllare che non ci siano allucinazioni ed errori ortografici." A quanto ci risulta, IBM è l'unica a inserire un avviso che invita a prendere con cautela quanto prodotto da un'IA, nonostante tutti i sistemi di questo tipo siano ugualmente vittima di allucinazioni e di errori vistosi (l'ultimo esempio in ordine cronologico viene da Google e dai suggerimenti di mettere la colla sulla pizza, ad esempio).
A ulteriore conferma dell'impegno di IBM nello sviluppo "aperto" di modelli d'IA, l'azienda ha annunciato con Red Hat (che, ricordiamo, ha acquisito cinque anni fa) InstructLab, che consente di sviluppare i modelli di base in maniera incrementale simile a quanto avviene già da decenni con il codice open source.
I modelli Granite fungono da base per gli assistenti watsonx, che includono diverse nuove versioni: Code Assistant for Enterprise Java Applications (disponibile a ottobre 2024), Assistant for Z per "trasformare il modo in cui gli utenti interagiscono con il sistema per trasferire rapidamente conoscenze e competenze" (come riportato dal comunicato stampa) e un'espansione di Code Assistant for Z Service che spiega il codice e aiuta così le aziende a documentare e sviluppare le applicazioni.
A partire da giugno 2024, inoltre, sarà disponibile IBM Concert, uno strumento fondato sull'IA generativa che fornisce suggerimenti per identificare e prevedere i problemi e fornire soluzioni. Il nuovo strumento si integra con i sistemi esistenti, siano essi infrastrutture in cloud, pipeline CI/CD o soluzioni di gestione delle applicazioni.
L'ecosistema watsonx si amplia

watsonx prende sempre più le sembianze di un vero e proprio ecosistema, con un numero crescente di partner e con la disponibilità di modelli di terze parti all'interno del servizio. Di seguito trovate una carrellata delle novità.
Adobe sta collaborando con IBM sul cloud ibrido e sull'IA: le due aziende porteranno Red Hat OpenShift e watsonx sulla Adobe Experience Platform e stanno esplorando la possibilità di rendere watsonx.ai e Adobe Acrobat AI Assistant disponibili on-premise e nel cloud privato.
AWS sta lavorando per unire Amazon SageMaker con watsonx.governance su AWS, così che le aziende che sfruttano SageMaker di semplificare la gestione e il monitoraggio dei propri modelli su tutte le piattaforme.
Sulla piattaforma watsonx diventerà disponibile Llama 3, modello di Meta con la quale IBM ha avviato una collaborazione all'interno della AI Alliance.
C'è una collaborazione anche con Microsoft Azure, sulla quale IBM supporta ora watsonx in maniera ufficiale.
Annuncio importante è quello sulla collaborazione con Mistral, azienda francese con la quale IBM ha annunciato l'intenzione di avviare una partnership strategica per portare i modelli di Mistral (incluso Mistral Large) su watsonx.
Palo Alto Networks ha ampliato la partnership con IBM con offerte congiunte legate alla sicurezza e basate sull'IA.
Salesforce sta valutando l'adozione dei modelli IBM Granite entro la fine dell'anno all'interno della piattaforma Salesforce Einstein 1, così da aumentare la varietà di modelli disponibili all'interno del CRM.
Anche SAP sta collaborando con IBM per integrare le soluzioni Watson AI all'interno delle soluzioni SAP; in particolare, i modelli Granite saranno accessibili nell'intero portfolio di servizi e soluzioni cloud di SAP.
Non manca una collaborazione con SDAIA, la Saudi Data and Artificial Intelligence Authority, per portare il modello ALLaM (che, per quanto possa sembrare altrimenti, non è un nostro errore né un tentativo di prendersi gioco della fede musulmana, ma proprio il nome ufficiale del progetto) su watsonx per rafforzare la competenza sulla lingua araba e i suoi vari dialetti.
Il punto di vista di Sebastian Krause sull’approccio di IBM all’IA
A margine dell’evento abbiamo potuto rivolgere alcune domande al Senior Vice President di IBM e sono emersi degli spunti davvero interessanti. Riportiamo quindi per intero la conversazione.
Edge9: Abbiamo due domande per Sebastian Krause. Una è più ampia, l'altra è più tecnica e specifica. Al Think sono state annunciate diverse partnership. Alcuni dei partner potrebbero anche essere visti come concorrenti, ora che state lanciando i modelli Granite. Mi riferisco in particolare ad AWS. Come gestite queste partnership? La seconda domanda riguarda InstructLAb. IBM scritto che è diverso dal RAG e che è migliore del RAG. Può spiegare meglio questo punto?

Sebastian Krause: Per quanto riguarda il primo punto, in particolare AWS, e posso includere anche Microsoft Azure, entrambi sono partner dell'ecosistema. Quindi stiamo sfruttando l’infrastruttura (di AWS, ndr) per le funzionalità che portiamo sul mercato attraverso i nostri prodotti software. Solo tre settimane fa abbiamo annunciato che con AWS Marketplace i nostri prodotti sono ora disponibili in 92 Paesi del mondo. E stiamo continuamente ampliando i set di prodotti disponibili su AWS Marketplace, man mano che continuiamo a sviluppare i nostri prodotti e a lanciarli. Allo stesso modo o in misura minore, in termini di disponibilità, vale per Azure. Ma vedrete che continueremo a lavorare anche con Microsoft per portare altri prodotti sul Marketplace. Questo è un modo molto naturale per noi di sfruttare l'ecosistema. Entrambe le aziende sono nostri ottimi partner. E l'infrastruttura che stanno fornendo è un'infrastruttura che molti dei nostri clienti utilizzano e vogliono sfruttare le nostre capacità software attraverso quei marketplace e quelle infrastrutture, quindi questa partnership, che va molto in profondità anche nelle capacità tecnologiche, ha molto senso.
Per quanto riguarda la seconda domanda, relativa a InstructLab, perché è diverso da RAG? InstrucLab prende i dati che state aumentando o che avete a portata di mano. Poi moltiplica quei dati in modo sintetico, per generare una serie di dati sintetici attraverso una tecnologia che chiamiamo LAB, sviluppata da IBM Research. I dati sintetici vengono poi sovrapposti al modello di base esistente. Quindi, grazie agli algoritmi di InstrucLab, si raggiunge un livello di precisione molto più elevato rispetto al modello di base iniziale. L'idea è che non si debba aprire un large language model e modificare l'intero set di dati, il che costa molto se si pensa a quanto si paga per un'infrastruttura GPU. E l'intero processo richiede molto, molto tempo. Se invece si procede nel modo appena descritto, è possibile farlo in una frazione del tempo e con una frazione delle risorse necessarie dal punto di vista delle GPU. Ecco perché riteniamo che il settore sia stato rivoluzionato, perché ora è possibile sfruttare i modelli di base esistenti con i propri dati e iterare in modo molto più rapido attraverso la tecnologia per raggiungere livelli di precisione significativamente superiori a quelli che si otterrebbero altrimenti.
Edge9: Una precisazione: vediamo che Granite è potenzialmente in concorrenza con AWS Bedrock e che sarà in concorrenza con AWS in alcuni stack della piattaforma AI generale. Qual è la sua visione?
Sebastian Krause: Consideriamo specificatamente i foundation model. Oggi sul mercato è disponibile un'ampia gamma di foundation model, Quindi c'è sicuramente una concorrenza sul mercato che non si può negare. Ma credo che la domanda sia: che tipo di foundation model si sta cercando e che tipo di tecnologia si vuole utilizzare? È meglio utilizzare un modello proprietario, che non è open source e che non si può sapere esattamente che tipo di dati sono stati inseriti in quel modello di base? Dal punto di vista di IBM, stiamo indennizzando i clienti per i nostri modelli di base della serie Granite, per il copyright e per la proprietà intellettuale, perché sappiamo quanto sia importante che i clienti sappiano esattamente che tipo di dati verranno pubblicati o utilizzati attraverso le funzionalità di IA generativa, perché se all'improvviso si pubblicassero contenuti inappropriati, ad esempio, si potrebbe danneggiare in modo significativo la reputazione di un'azienda. Quindi questo indennizzo è estremamente importante per i clienti, ma ancora più importante è la sicurezza, per così dire, di poter fare affidamento sui dati che non saranno dannosi.
E questo è un elemento di differenziazione che ci permette di indennizzare i nostri modelli sia per il copyright che per la proprietà intellettuale. L'altra parte, in termini di concorrenza, è ovviamente l'accuratezza del modello. Quali sono i dati che sono stati inseriti nel modello? E per quali casi d'uso e per quali scopi si desidera utilizzare il modello? Ecco perché ho detto che abbiamo modelli linguistici di grandi dimensioni che hanno un'accuratezza molto elevata e che è possibile scegliere un modello più piccolo di tre miliardi di parametri che potrebbe avere un'accuratezza maggiore rispetto a un altro modello con cui siamo in competizione che potrebbe avere 70 miliardi di parametri che saranno anche molto più costosi in termini di tempo di calcolo necessario. Quindi c'è anche un vantaggio nei modelli più piccoli. L'altra parte è che vogliamo creare modelli che non siano solo linguistici, ma anche geospaziali, di serie temporali o di settori specifici. Tutto questo viene costruito nella nostra infrastruttura GPU con dati che fondamentalmente abbiamo o che acquisiamo o che otteniamo dal settore pubblico, ma pubblicheremo sempre i documenti scientifici su come questi dati sono stati costruiti, come sono stati spostati nel modello di base in modo che ci sia piena trasparenza sulla provenienza dei dati.



 TCL 65C7K, televisore Mini-LED di qualità, versatile e dal prezzo competitivo
TCL 65C7K, televisore Mini-LED di qualità, versatile e dal prezzo competitivo Fujifilm X-E5: la Fuji X che tutti gli appassionati volevano
Fujifilm X-E5: la Fuji X che tutti gli appassionati volevano Recensione REDMAGIC 10S Pro: il gaming phone definitivo?
Recensione REDMAGIC 10S Pro: il gaming phone definitivo? Fairphone 6 conquista iFixit: riparabilità da 10 e filosofia etica
Fairphone 6 conquista iFixit: riparabilità da 10 e filosofia etica Windows Classic Remastered: il sistema operativo immaginario che fonde passato e presente
Windows Classic Remastered: il sistema operativo immaginario che fonde passato e presente Crollo di prezzi in Amazon: oltre 50 prodotti in super sconto fra cui AirPods, iPhone, robot, portatili, tablet e molto altro
Crollo di prezzi in Amazon: oltre 50 prodotti in super sconto fra cui AirPods, iPhone, robot, portatili, tablet e molto altro















0 Commenti
Gli autori dei commenti, e non la redazione, sono responsabili dei contenuti da loro inseriti - infoDevi effettuare il login per poter commentare
Se non sei ancora registrato, puoi farlo attraverso questo form.
Se sei già registrato e loggato nel sito, puoi inserire il tuo commento.
Si tenga presente quanto letto nel regolamento, nel rispetto del "quieto vivere".