






NVIDIA annuncia la versione 6 di CUDA e unifica la memoria virtuale
di Paolo Corsini pubblicata il 15 Novembre 2013, alle 08:41 nel canale Private CloudImportante annuncio di NVIDIA nell'ottica del lavoro che i programmatori devono svolgere per portare le proprie applicazioni a sfruttare le GPU NVIDIA per calcoli paralleli non grafici.
Importante annuncio da parte di NVIDIA, il primo di quelli che saranno una lunga serie visto l'approssimarsi di Supercomputing13: si tratta della release 6 di CUDA, il proprio linguaggio di programmazione adottato per quegli scenari di elaborazione nei quali si voglia utilizzare la GPU quale alternativa alle tradizionali CPU.
La novità principale della release 6 di CUDA riguarda l'integrazione di un approccio unificato alla memoria, per la prima volta presente nel linguaggio di programmazione di NVIDIA. Questo semplifica la gestione della memoria, e quindi il lavoro dello sviluppatore software, in misura molto elevata.
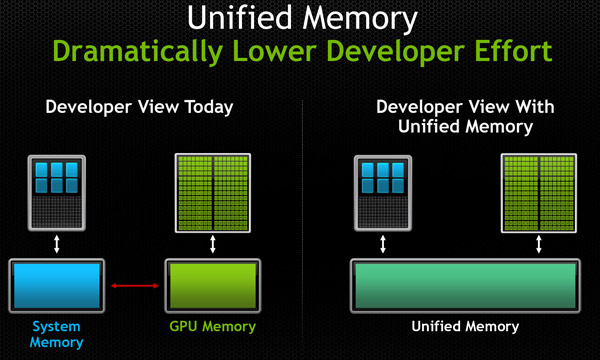
In che modo avviene questo? Lo sviluppatore software, con Unified Memory, può accedere a qualsiasi risorsa o indirizzo di memoria indipendentemente da dove questa sia presente, di fatto non richiedendo più che il programmatore debba andare a specificare la copia da e verso la GPU dei dati contenuti in memoria in quanto queste operazioni saranno svolte direttamente da CUDA.
D'altro canto memoria di sistema e memoria della scheda video rimangono due componenti fisici separati: questo implica che saranno sempre richieste operazioni di copia dei dati dalla memoria alla GPU ma queste avverranno senza diretta richiesta del programmatore, che potrà vedere il tutto ad alto livello come unificato.
L'implicazione diretta è quindi una superiore facilità per il programmatore, non un impatto positivo in termini di prestazioni velocistiche: trattandosi di una tecnica di astrazione della memoria è ipotizzabile che questo approccio possa portare ad un impatto prestazionale, che quantomeno al momento attuale NVIDIA non quantifica.
L'evoluzione futura delle architetture di GPU NVIDIA punta in ogni caso verso uno spazio di memoria virtuale unificato: è questa una caratteristica tecnica delle soluzioni della famiglia Maxwell che NVIDIA ha già anticipato negli scorsi mesi, prodotti che debutteranno sul mercato a partire dal prossimo anno. La presumibile differenza tra l'approccio attuale con CUDA 6 e quello atteso con Maxwell è legato alla logica solo software del primo, e alla presumibile presenza di qualche componente hardware nelle GPU Maxwell che dovrebbe permettere di gestire con maggiore efficienza l'unified virtual memory.



 HP Elitebook Ultra G1i 14 è il notebook compatto, potente e robusto
HP Elitebook Ultra G1i 14 è il notebook compatto, potente e robusto Microsoft Surface Pro 12 è il 2 in 1 più compatto e silenzioso
Microsoft Surface Pro 12 è il 2 in 1 più compatto e silenzioso Recensione REDMAGIC Astra Gaming Tablet: che spettacolo di tablet!
Recensione REDMAGIC Astra Gaming Tablet: che spettacolo di tablet!  MetaMask, bug nel wallet crypto: distrugge il tuo SSD senza che tu lo sappia
MetaMask, bug nel wallet crypto: distrugge il tuo SSD senza che tu lo sappia Motorola edge 50 Neo 12/512GB o edge 60 8/256GB? Oggi scontati a circa 260 entrambi, quale prendere?
Motorola edge 50 Neo 12/512GB o edge 60 8/256GB? Oggi scontati a circa 260 entrambi, quale prendere? Dick Pic addio? L'AI di Flirtini insegna agli uomini a fare sexting rispettando le donne (e se stessi)
Dick Pic addio? L'AI di Flirtini insegna agli uomini a fare sexting rispettando le donne (e se stessi)















8 Commenti
Gli autori dei commenti, e non la redazione, sono responsabili dei contenuti da loro inseriti - info^ THIS
Nel senso che dai a CUDA più lavoro da fare nel momento dell'esecuzione del codice: deve fare tutto quello sbattimento che toccava al programmatore nel dividere le due memorie e cercare gli indirizzi alle quali si riferiscono, ogni volta che esegui il programma (nel caso precedente, lo facevi una volta sola). Ergo, i calcoli aumentano e le prestazioni ne risentono. GG NVIDIA.
Poi, in generale, si. Ad alti livelli di astrazione si ha un'ottimizzazione minore rispetto a livelli più bassi (tipo Assembler).
Devi effettuare il login per poter commentare
Se non sei ancora registrato, puoi farlo attraverso questo form.
Se sei già registrato e loggato nel sito, puoi inserire il tuo commento.
Si tenga presente quanto letto nel regolamento, nel rispetto del "quieto vivere".