






I supercomputer visti da dentro: ne parliamo con l'Università di Cambridge
di Riccardo Robecchi pubblicata il 23 Luglio 2020, alle 15:21 nel canale Private Cloud
Abbiamo intervistato Paul Calleja, direttore dei Research Computing Services dell'Università di Cambridge, e gli abbiamo chiesto come si sta evolvendo il settore dell'HPC, a partire dal supercomputer dell'università costruito con Dell Technologies e Intel
Come si stanno evolvendo i supercomputer? Come sta cambiando l'archiviazione nel mondo del calcolo ad alte prestazioni? Quali risultati permettono di ottenere le nuove tecnologie? Abbiamo parlato di questo e altro con Paul Calleja, direttore dei Research Computing Services dell'Università di Cambridge. L'università ha recentemente inaugurato un nuovo sistema di storage per il suo supercomputer Cumulus: basato su SSD NVMe e sviluppato insieme a Dell Technologies e Intel, il sistema permette di aumentare sensibilmente le prestazioni di una vasta gamma di applicazioni.
Il mondo HPC: un'evoluzione dettata dai dati

I supercomputer sono oggi formati anche da centinaia di server, distribuiti su decine o centinaia di armadi rack che arrivano a occupare aree paragonabili ai campi di calcio, e connessi fra di loro da reti ad alta velocità. Se ne parla spesso come di oggetti quasi astratti, vista la loro dimensione estremamente elevata che rende difficile anche solo immaginarli come oggetti fisici nel loro complesso.
Utilizzati per la ricerca sia in ambito accademico che in ambito industriale, i supercomputer sono estremamente più potenti rispetto a qualche anno fa, ma sono ancora limitati da fattori come la velocità di trasferimento dei dati tra i vari nodi.
"Se torniamo indietro di dieci anni, il principale collo di bottiglia veniva dai processori. I requisiti di I/O erano relativamente bassi e i dataset erano relativamente ridotti. Oggi siamo in un mondo completamente differente. Cinque o sei anni fa abbiamo cominciato a vedere una crescita rapida dei dataset - noi lavoriamo con esperimenti di varia natura che producono una quantità enorme di dati - e questo significa che nel mondo HPC bisogna ora elaborare grandi volumi di dati. Un'altra cosa che è cambiata è che i sistemi HPC sono molto, molto più grandi ora. Bisogna immaginare sistemi con migliaia, decine o centinaia di migliaia di core [di CPU]. Questi core devono ottenere i dati e con i sistemi HPC che crescono e diventano sempre più grandi - molto più di quanto fossero in passato - i core devono parlare con dei sistemi di archiviazione condivisi."
È a questo punto che emergono i problemi di prestazioni. "Ci sono queste centinaia di migliaia di core che fanno girare anche 1000 o 2000 processi. Ciò significa che le prestazioni aggregate del sistema di archiviazione possono essere elevate, ma un singolo processo non viene distribuito su tutti i dischi: questo significa che le sue prestazioni possono essere piuttosto basse. Ed è qui che le nuove tecnologie, come i dischi a stato solido, possono diventare interessanti."
Normalmente si effettua lo striping, ovvero la distribuzione dei dati su tutti i dischi, così da incrementare le prestazioni di lettura e scrittura. "Se dividi su tutte le reti il tuo processo ottieni certamente un vantaggio prestazionale, ma nel mondo reale il tuo non è l'unico processo che usa la rete. Con i dischi NVMe non c'è questo tipo di interferenza." L'università di Cambridge ha creato un sistema che sfrutta Slurm, un software per la gestione dei processi (un workload scheduler, per la precisione), per creare una cache sui dischi NVMe: si copiano i dati dai dischi tradizionali agli SSD, si eseguono i calcolo e si spostano nuovamente i dati sui dischi. "In questo modo possiamo creare un file system temporaneo, che non ha bisogno di tutti i controlli per assicurare la resilienza, e questo ci permette di aumentare ancora di più le prestazioni."
Il Data Accelerator: dischi NVMe Intel su server Dell per le massime prestazioni
Ecco perché l'Università di Cambridge ha sviluppato il DAC, o Data Accelerator: una serie di nodi contenenti server con dischi NVMe Intel Optane. Grazie al DAC è possibile aumentare le prestazioni del supercomputer universitario, in particolare per tutte quelle applicazioni che richiedono una bassa latenza. Calleja afferma che la latenza media è scesa ad appena 1 microsecondo: ben al di sotto di quella garantita dai dischi tradizionali a piatti rotanti. "La latenza è uno o due ordini di grandezza più piccola rispetto alle soluzioni tradizionali, anche perché i dischi NVMe comunicano direttamente con la rete Infinity Fabric."
La domanda che sorge, però, è se sia più importante la latenza o l'ampiezza di banda nel mondo HPC. "Questo è in realtà il cuore della questione. Quando abbiamo iniziato questo progetto, ci siamo chiesti (e abbiamo chiesto a Intel) come potessimo costruire il server con dischi NVMe che ci permettesse di ottenere i numeri migliori nei benchmark. Come possiamo assicurarci di ottenere le massime prestazioni in termini di banda e IOPS di picco? Se prendo un server Dell, quando arrivo al massimo [di prestazioni] se continuo ad aggiungere dischi? Posso avere maggiore capacità, ma andando oltre un certo punto saturerò la banda disponibile, dettata dalle linee PCI-Express disponibili e dalla rete. Nel caso della nostra rete, il nostro limite è di 22 gigabyte al secondo."
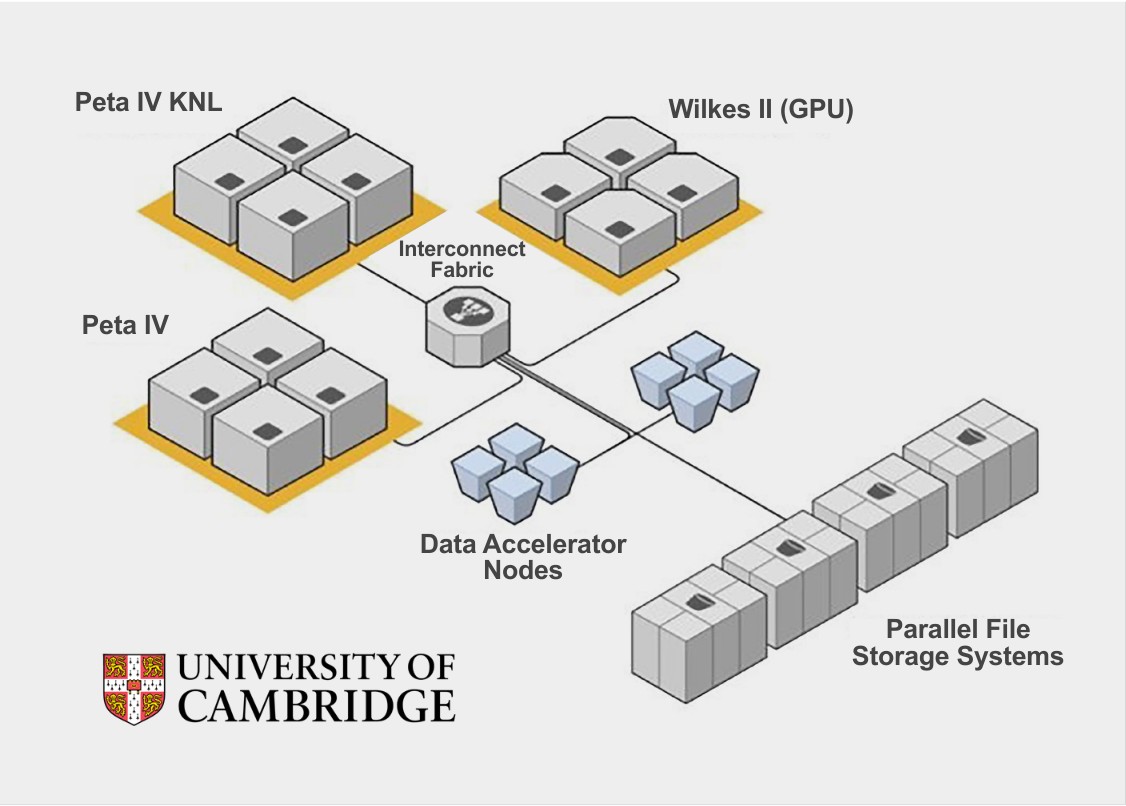
Il DAC è costruito usando 24 server Dell EMC PowerEdge R740xd 2U, ciascuno con due processori Intel Xeon Gold da 16 core operanti a 2,5 GHz e sei SSD P4610 per ciascuna CPU, per un totale di 12 SSD per ciascun server. È stato pubblicato un whitepaper al riguardo e il codice sorgente del software è disponibile su GitHub. Dell Technologies, inoltre, rende disponibile il sistema
"Il problema è che, alla fine, dipende da quello di cui ha bisogno l'applicazione: alcune sono sensibili alla banda, altre sono limitate dai metadati, altre ancora dalle IOPS. In questi casi bisogna profilare l'applicazione e capire di cosa ha bisogno e trovare il giusto compromesso. Questa è la fase più lenta", continua Calleja, "e richiede di collaborare con il cliente, perché molte applicazioni non sono ottimizzate, magari perché sono state scritte dieci anni fa, quando i computer erano completamente diversi, e non sono ottimizzate per sfruttare le prestazioni dei dispositivi di archiviazione."
"L'hardware è più avanti del software e i produttori continuano a creare nuove tecnologie che poi bisogna capire come sfruttare", afferma Calleja. "Prima è il software di sistema a dover recuperare il divario con l'hardware, ed è quello che abbiamo fatto con il DAC, poi tocca alle applicazioni."
Una delle operazioni che traggono maggiormente vantaggio dai nuovi dischi è il cosiddetto checkpoint: dopo un certo numero di ore di esecuzione, l'applicazione viene messa in pausa e il contenuto della memoria trasferito sui dischi per salvarlo. Questo è un processo tradizionalmente lungo, che può richiedere ore; con i dischi NVMe è possibile ridurlo nettamente e questo è un aspetto di cui tutte le applicazioni possono giovare.
Il risultato pratico di tutto questo è duplice: i tempi di esecuzione si riducono, così come i costi. Nel mondo della ricerca questo può fare la differenza, dato che minori costi e tempi per l'elaborazione dei dati possono influire sulla quantità di esperimenti da fare e quindi, in ultima analisi, sulle scoperte effettuate.
Uno sguardo al futuro tra architetture specializzate ed esigenze in cambiamento
Qualche mese fa Fujitsu ha annunciato il nuovo supercomputer Fugaku: non solo è il più potente del mondo, ma anche il più efficiente in assoluto. Questo nuovo supercomputer utilizza processori basati su architettura ARM e sviluppati specificamente per l'utilizzo nell'ambito dell'HPC. Con la richiesta di sempre maggiori prestazioni sembra arrivato il momento che il mondo HPC si differenzi dal resto con architetture ad hoc.
"Il modo migliore di guardare al futuro è guardare al passato", ci dice Calleja. "Se consideriamo le macchine di punta giapponesi, molto molto raramente ne vengono prodotti due esemplari. Sono macchine che esplorano ciò che è possibile fare, le cui innovazioni poi compaiono altrove. Secondo me sono molto utili come esperimenti, ma credo piuttosto sia molto più interessante capire come rendere il calcolo ad alte prestazioni una commodity, come produrre una maggiore quantità di sistemi a un costo inferiore."

Costruire i supercomputer finora è stato piuttosto costoso e proprio l'aspetto del costo è stato tra quelli che hanno finora frenato la costruzione di grandi supercomputer nel settore pubblico in Italia, ad esempio.
"Quando sono stato assunto a Cambridge c'era un supercomputer con 18 teraflop di potenza. Non riesco nemmeno a immaginarlo ora: 18 teraflop! Questa macchina occupava 25 armadi, consumava 200 kilowatt, era costata 2 milioni di sterline ed era la numero 20 nella classifica top 500. 20 teraflop ora sono una sola scheda grafica! In un solo server 2U si possono ottenere 50 teraflop. È un decremento gigantesco del prezzo per teraflop. Di contro, il costo per rimanere nella classifica dei migliori supercomputer è cresciuto drammaticamente." Calleja propone un altro punto di vista: "è cambiato, però, anche il mondo della ricerca: la maggior parte dei ricercatori ha bisogno di una piccola parte della potenza complessiva, non di un supercomputer intero. Il mondo dell'HPC è cambiato e gli utenti sono ora molti, molti di più, che utilizzano una piccola fetta delle risorse: abbiamo una coda lunga. L'HPC non è diventato più costoso, è anzi diventato più economico; è rimanere in questa sorta di corsa alle armi a chi ha il supercomputer più potente che è diventato più costoso."
L'HPC è molto più facile ed economico da utilizzare rispetto a quanto fosse in passato. E Calleja suggerisce che, alla fine, sia solo una questione di definizione: "cos'è un supercomputer oggigiorno? Dieci nodi? Venti nodi? Un computer con quattro GPU all'interno?" Di fatto un computer casalingo di fascia alta oggigiorno ha più potenza di calcolo del più potente supercomputer di vent'anni fa.
E il cloud sta portando ulteriore cambiamento: "c'è sempre maggiore interazione tra l'infrastruttura locale e quella in cloud e questo sta cambiando il modo in cui la gente usa i supercomputer - di nuovo, diventa sempre più una commodity, meno costosa e più facile da usare. E dal momento che parliamo di dataset piuttosto grandi, non è facile spostarli nel cloud - e quindi portiamo il cloud nel nostro supercomputer. Forniamo ai nostri clienti gli stessi strumenti, le stesse toolchain, in modo che possano avere la stessa flessibilità del cloud."
Una questione di approccio: perché Cambridge sceglie l'open source
L'Università di Cambridge ha scelto un approccio aperto nello sviluppo del Data Accelerator, concretizzatosi nel rendere il codice open source. Cambridge ha sempre adottato questo modello, come ci dice Calleja: "il costo è la motivazione principale, perché il software open source e l'hardware che segue standard aperti abbassano i costi rispetto alle soluzioni proprietarie. La seconda è la flessibilità, unita al minor tempo di implementazione delle novità tecnologiche. C'è anche un fattore di condivisione della proprietà: in questo modo siamo comproprietari delle soluzioni sviluppate insieme ai nostri partner industriali. Questo significa anche che possiamo modificare le soluzioni in base alle nostre esigenze. Se non tenessimo questo approccio", continua Calleja, "saremmo costretti dentro l'offerta di uno specifico produttore. In questo modo abbiamo anche reso più semplice l'esplorazione di queste soluzioni per il mondo della ricerca."
OpenStack è una delle tecnologie open source che Calleja menziona: "Utilizziamo OpenStack per la nostra infrastruttura, utilizzando tecnologie native del cloud. In questo modo diventa molto più facile portare le applicazioni dei clienti sul cloud e dal cloud. Secondo me ci sarà una convergenza in futuro tra computer locali e cloud, almeno nel mondo della ricerca. Al CERN usano già OpenStack, lavorano con i container e con la virtualizzazione."
OpenStack è uno standard aperto e sfrutta tecnologie open source, motivo per cui si sta imponendo nel mondo del cloud, in particolare quando si lavora in ambienti ibridi. Il supercomputer Cumulus, costruito con 700 server Dell, sfrutta proprio OpenStack per la gestione delle risorse.
Quanto ci ha detto Calleja ci permette di dipingere un quadro del futuro in cui i supercomputer sono macchine tutto sommato piccole, ma altamente interconnesse e basate su piattaforme sia hardware che software aperte. Saranno più diffusi e più accessibili, così che sarà possibile fare più ricerca: con una spesa relativamente ridotta sarà possibile acquistare macchine sufficientemente potenti da soddisfare le esigenze di calcolo dei gruppi di ricerca, senza dover ricorrere ai mastodonti che occupano le prime posizioni nelle classifiche (con gli investimenti a questo punto miliardari che richiedono). Maggiore facilità nell'ottenere le risorse di calcolo necessarie, costi minori per lo sviluppo delle ricerche e maggiore agilità per i ricercatori potrebbero portare a un'accelerazione di quello che Calleja chiama "time to science", ovvero il tempo che ci vuole per produrre dei risultati scientifici concreti. Il concetto di supercomputer come macchina che occupa un intero data center viene in questo modo messo in discussione - e non è detto che sia un male.



 HP Elitebook Ultra G1i 14 è il notebook compatto, potente e robusto
HP Elitebook Ultra G1i 14 è il notebook compatto, potente e robusto Microsoft Surface Pro 12 è il 2 in 1 più compatto e silenzioso
Microsoft Surface Pro 12 è il 2 in 1 più compatto e silenzioso Recensione REDMAGIC Astra Gaming Tablet: che spettacolo di tablet!
Recensione REDMAGIC Astra Gaming Tablet: che spettacolo di tablet!  Finalmente rilevata la stella compagna della supergigante rossa Betelgeuse, nella costellazione di Orione
Finalmente rilevata la stella compagna della supergigante rossa Betelgeuse, nella costellazione di Orione UBTech Walker S2: il robot umanoide cinese che si cambia la batteria da solo
UBTech Walker S2: il robot umanoide cinese che si cambia la batteria da solo Musk guarda ai più piccoli: in arrivo Baby Grok, l'IA rivolta ai bambini
Musk guarda ai più piccoli: in arrivo Baby Grok, l'IA rivolta ai bambini















4 Commenti
Gli autori dei commenti, e non la redazione, sono responsabili dei contenuti da loro inseriti - infoLa domanda che sorge a me leggendoti, invece, è come mai chi scrive in un sito di tecnologia informatica non conosca la terminologia tecnica di base. In italiano non puoi usare "banda passante" al posto di "ampiezza di banda", perché le due espressioni hanno significati molto differenti e appartengono a due ambiti ben distinti. Banda passante indica l'ampiezza di un intervallo di frequenze, ed è un concetto fisico che attiene all'elettronica analogica o alla tecnologia delle trasmissioni radio. Ampiezza di banda indica invece la quantità di dati che può transitare nell'unità di tempo in un determinato percoso dati digitale, ed è un concetto che attiene all'informatica.
In inglese si utilizza lo stesso termine "bandwidth" in due accezioni diverse, perciò quando traduci qualcosa da quella lingua devi scegiere l'espressione italiana corretta in base al contesto.
Sono al corrente della differenza tra "banda passante" e "ampiezza di banda". Semplicemente capita, di quando in quando, di fare degli errori: sono umano anche io. Ti auguro di trovare persone comprensive quanto lo sei tu, quando farai tu degli errori.
/OT
Devi effettuare il login per poter commentare
Se non sei ancora registrato, puoi farlo attraverso questo form.
Se sei già registrato e loggato nel sito, puoi inserire il tuo commento.
Si tenga presente quanto letto nel regolamento, nel rispetto del "quieto vivere".