






La rivoluzione dei dati in tempo reale è in arrivo. Un assaggio a Confluent Current 2025
di Riccardo Robecchi pubblicato il 30 Maggio 2025 nel canale Innovazione
Siamo andati a Londra per partecipare a Current 2025, la conferenza annuale di Confluent. Il tema al centro dell'evento era l'elaborazione dei dati in tempo reale resa possibile da Apache Kafka, una piattaforma open source pensata proprio per questo. Si è parlato di come stia cambiando la gestione dei dati in tempo reale, del perché sia importante e di quali siano le prospettive per il futuro
I dati sono alla base di tutte le attività aziendali. Di più: secondo Jay Kreps, CEO di Confluent, la tecnologia è diventata così fondamentale che le aziende si basano oggi sul software, qualunque sia il loro settore di appartenenza. Un'affermazione indubbiamente forte e tutt'altro che scontata, nonostante negli anni abbiamo visto un aumento evidente dell'importanza della tecnologia nelle aziende. Ma la sempre maggiore digitalizzazione e l'arrivo dell'IA stanno cambiando ulteriormente le carte in tavola. Siamo andati a Current, la conferenza annuale di Confluent, per capire in che modo.
I dati in tempo reale, un problema sempre più attuale

La quarta rivoluzione industriale ha portato i dati ovunque o, per meglio dire, ha raccolto dati da dovunque: dove prima c'erano attività spesso molto "analogiche", ora ci sono sensori e procedure informatiche che consentono di raccogliere dati da più o meno qualunque cosa. Con la crescita dell'IoT, questo fenomeno si è ulteriormente ampliato. Il problema ora è gestire questi dati, in particolare in tempo reale.
Fino a poco tempo fa, i dati erano elaborati in batch, ovvero in lotti: per avere un esempio pratico, basti pensare al modo in cui funziona(va)no i sistemi delle banche, in cui l'inserimento di un ordine di bonifico non portava all'esecuzione immediata dello stesso, ma all'inserimento di un ordine che veniva poi eseguito insieme a tutti gli altri durante la notte. Lo stesso avveniva alla ricezione: tutti i bonifici ricevuti venivano elaborati assieme.
Va da sé come questo modello non sia funzionale per tutti i casi d'uso. Immaginiamo di essere un viaggiatore che si trova bloccato in una stazione perché il suo treno è stato cancellato e ci sono ulteriori ritardi dovuti a un problema sulla linea (ad esempio, perché qualcuno ha piantato un chiodo dove non doveva e nessuno si è premurato di verificare che gli UPS funzionassero): se i dati vengono elaborati in blocchi, non ci saranno informazioni affidabilisullo stato attuale dei treni e anche il sito Web degli operatori ferroviari non riporterà informazioni aggiornate e corrette.

Questo è il problema che una piattaforma come Apache Kafka, progetto open source su cui si basa quella di Confluent, cerca di risolvere: fornire dati in tempo reale che siano analizzabili e affidabili quanto quelli che vengono gestiti tramite i database tradizionali e l'approccio "a blocchi". Kafka gestisce flussi di dati (in inglese "stream", da cui deriva il termine più generico "data streaming") da fonti disparate e li rende gestibili a livello centralizzato e con strumenti che consentono di effettuarne l'analisi e l'elaborazione in tempo reale, senza la necessità di archiviarli e catalogarli prima di poterli elaborare.
Il problema di Kafka è che è estremamente complesso e richiede intere squadre di persone semplicemente per continuare a funzionare correttamente. Confluent ha fatto la sua fortuna grazie alla creazione di strumenti che consentono di semplificare nettamente queste operazioni e di integrare la piattaforma direttamente con le principali piattaforme cloud.
Il passaggio dall'elaborazione dei dati in batch a quella in flussi comporta un cambiamento non solo a livello tecnico, ma anche a livello culturale all'interno dell'azienda, perché cambia completamente l'approccio ai dati e alle applicazioni; dall'altro lato, è un passaggio reso quasi obbligatorio dall'evoluzione tecnologica, dalle aspettative delle aziende e dei loro utenti, e dalla necessità di gestire gli eventi in maniera più tempestiva.
"Non ci sono semplicemente più dati. Il ruolo del software non è più solo di archiviare e recuperare dati. Una volta, ci voleva l'intervento delle persone: quando l'utente si presentava alla scrivania, c'erano delle azioni. Il software ora prende le decisioni e lavora tutto il tempo, non serve più l'utente alla scrivania alle 9 del mattino", dice Kreps. "Le decisioni sono ora un'attività in tempo reale. L'intelligenza non è più solo nella testa delle persone, può essere nel software stesso."
Un cambio di paradigma che richiede di ripensare tutta l'architettura, a partire proprio da come i dati vengono raccolti e analizzati.
Le novità a Current 2025: Tableflow, Flink e le snapshot query

A Current 2025, Confluent ha presentato diverse novità che vanno a colmare il divario tra l'elaborazione dei dati tradizionale, ovvero in batch, e quella in streaming. L'azienda ha affermato che, grazie a queste novità, si può vedere l'elaborazione in streaming come una generalizzazione di quella in batch, poiché i dati vengono elaborati allo stesso modo. Nello specifico, le novità consistono in Tableflow, Flink e le snapshot query.
Il problema di gestire i dati in streaming con Apache Kafka sta nella complessità di archiviare i dati in maniera tale da renderli accessibili ai sistemi tradizionali d'elaborazione dei dati. Tableflow consente di fare proprio questo, poiché permette di archiviare i dati in un data lake, data warehouse o sistema di analisi come tabelle di Apache Iceberg o Delta Lake in maniera molto semplice ("con un click", stando a Confluent). In questo modo è molto più facile archiviare i dati e renderli poi disponibili ai vari sistemi di analisi e reportistica che consentono, ad esempio, di ottenere informazioni sul medio e lungo periodo.

Proprio la visione dei dati all'interno di un contesto è la ragione dietro Apache Flink, sistema che consente di unificare il modo in cui vengono trattati i dati in batch e in streaming. Flink ottiene questo risultato grazie a una rappresentazione dei dati in forma tabellare, che è possibile interrogare con linguaggi standard come SQL. In questo modo è possibile mettere insieme i dati in tempo reale, che arrivano in streaming, con quelli storici, che arrivano invece da sistemi come i database.
Un esempio che ci ha fatto Kai Wähner, Field CTO di Confluent, è quello di un sistema di raccomandazione in tempo reale all'interno di negozi fisici. Quando un cliente si reca alla cassa per pagare, un sistema che tratta solo i dati in tempo reale non ha accesso allo storico degli acquisti e non può, quindi, fornire raccomandazioni basate su di esso; viceversa, nel momento in cui si mettono insieme i dati in tempo reale (ciò che il cliente sta acquistando) e dati storici (ciò che è stato acquistato) consente al sistema di accedere a un contesto più ampio e, quindi, di fornire suggerimenti validi, come ad esempio uno sconto speciale su un oggetto che il cliente ha aggiunto alla lista dei desideri sul sito web del negozio. Un altro esempio fatto da Wähner è il controllo dei pagamenti fatti con una carta di credito: se un pagamento avviene a Londra con una carta italiana ma non si ha il contesto, ovvero che pochi minuti prima era stato effettuato un altro pagamento a Brindisi, non si riesce a rilevare che il pagamento londinese era in realtà fraudolento.
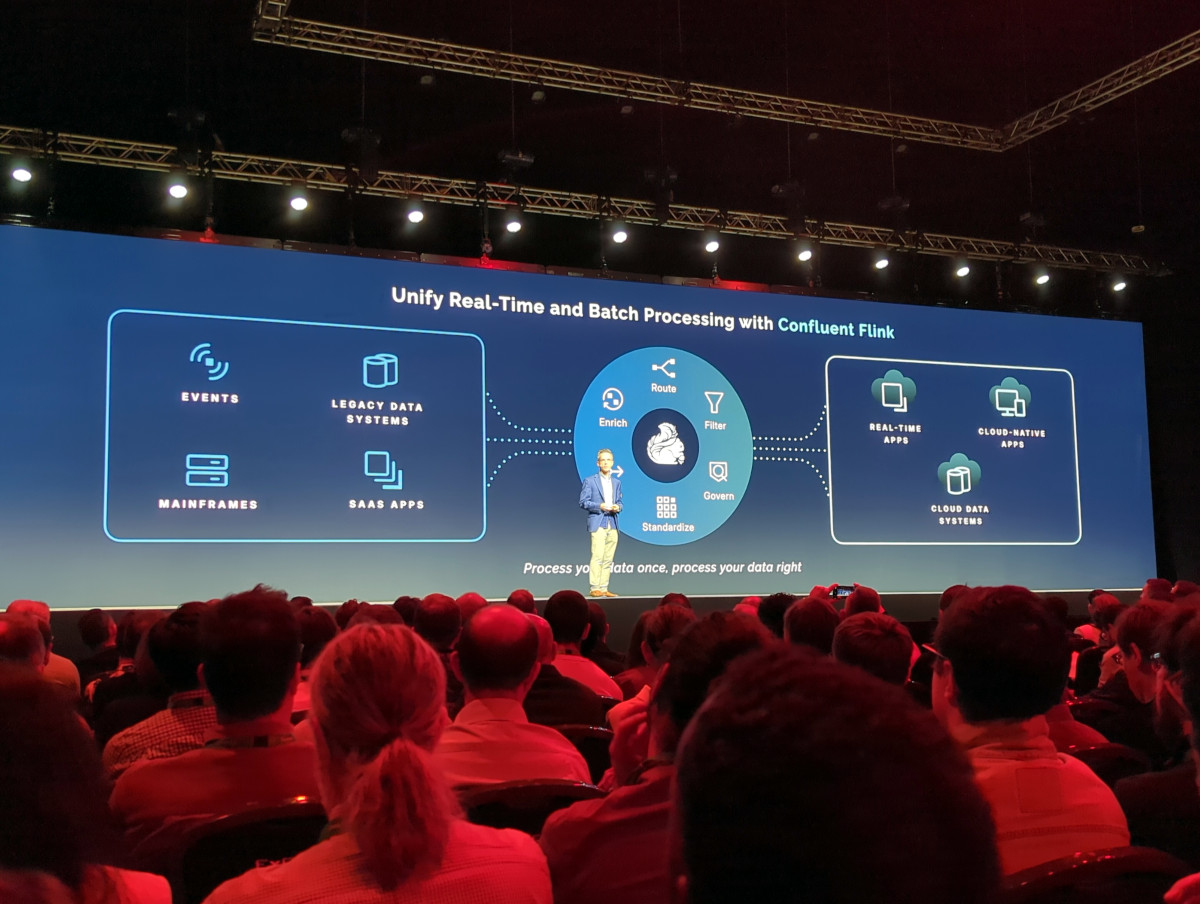
Le snapshot query continuano su questo percorso: consentono di prendere i dati di un certo momento (ad esempio, lo storico dell'ultima settimana) e continuare a integrarli con i dati che arrivano in tempo reale. Wähner fa l'esempio della manutenzione predittiva, in cui si prende lo storico dei dati rilevati dai sensori sui macchinari industriali e si continua a integrarlo con i nuovi dati che arrivano; in questo modo è possibile avere il contesto che permette di capire se il macchinario sta per avere problemi e d'intervenire prima che questi problemi si verifichino e portino a guasti.
Poter mettere insieme dati storici e dati in tempo reale cambia radicalmente le carte in tavola proprio perché consente di costruire sistemi che sono in grado di adattarsi alla situazione, perché sono al corrente del contesto. Avendo solo i dati storici non si riesce a intervenire in tempo reale (ad esempio, fermando il macchinario prima che si guasti), mentre avendo solo i dati in tempo reale non si ha l'informazione sul contesto che consente di mettere le cose nella giusta prospettiva (ad esempio, perché il macchinario gira a vuoto solo per un secondo e ciò fa registrare valori fuori scala senza, però, che ci sia effettivamente un guasto).
Verso l'unificazione di database e dati in tempo reale, con lo zampino dell'IA

Un passaggio significativo nella presentazione di Kreps è stato quando Kreps ha paragonato i log delle transazioni nei database allo streaming dei dati in tempo reale: le differenze sono, di fatto, nulle. Si può dunque vedere un database come il risultato dell'accumularsi di una serie di dati in tempo reale o, viceversa, i dati in tempo reale come una continua istantanea di un database. Il fatto che strumenti come Tableflow e Flink consentano di gestire questi due tipi di dati allo stesso modo, nonostante appaiano fondamentalmente diversi, sembra indicare che ci sia una convergenza che li porterà a unificarsi.
E questo è proprio quanto ci hanno detto più persone presenti alla conferenza: non solo ne abbiamo parlato con rappresentanti di Confluent, che ci hanno confermato come sempre più questa sia la direzione, ma anche con rappresentanti di MongoDB e Oracle, entrambe realtà che stanno integrando sistemi per gestire dati in tempo reale all'interno dei propri database.
In tutto questo non può, ovviamente, mancare una menzione dell'intelligenza artificiale. Come ci spiega Alberto Bullani, Area Vice President per il Sud Europa, il Medio Oriente e l'Africa, "alla base dell'IA ci sono i dati. Quello che fa Confluent è traportare i dati da sorgenti diverse ed elaborarli in tempo reale, così che il dato corretto, pulito e certificato venga portato poi nella piattaforma prescelta, ad esempio i database vettoriali da cui poi l'IA trae i dati."
Bullani aggiunge che "un'integrazione che funziona molto bene tra l'IA e Confluent è la cosiddetta RAG, retrieval augmented generation. Lì possiamo dare un grosso valore aggiunto rispetto alle query sui dati statici, ad esempio per fornire informazioni in tempo reale sui voli per le piattaforme di prenotazione o le linee aeree. Questo è il tipo di sperimentazione che vediamo tra i clienti nell'area EMEA oggi."
Come Confluent aiuta a prevenire i blackout
Un ulteriore esempio portato da Confluent di uso della sua piattaforma è l'azienda finlandese Virta Global, il cui nome in finlandese significa "potenza" nel senso di "energia elettrica, alimentazione elettrica". L'azienda si occupa di gestire le colonnine di ricarica per le automobili elettriche in numerosi Paesi. Ciascuna colonnina è dotata di sensori che rilevano l'erogazione di potenza alle automobili e, dall'altro lato, la stabilità della rete di distribuzione.
Nel momento in cui c'è un'instabilità, le colonnine di Virta la rilevano e trasmettono i dati al cloud: a quel punto c'è un sistema che decide se interrompere l'alimentazione alle automobili così da aiutare a ripristinare la stabilità della rete ed evitare un blackout. Il tempo di reazione è piuttosto basso: è necessario intervenire in appena cinque secondi. Va da sé, dunque, che non possa esserci una persona che interviene, ma debbano essere presenti sistemi automatizzati.

Secondo Jussi Ahtikari, CTO in Virta Global, il problema dell'instabilità sarà un tema sempre più presente mano a mano che una quota crescente dell'elettricità verrà prodotta tramite energie rinnovabili. Non mancano, però, soluzioni: in futuro sempre più batterie saranno installate proprio per far fronte a situazioni di calo della disponibilità di energia, e sarà possibile anche aiutare il ripristino della normalità in caso di instabilità usando le batterie delle automobili per brevi momenti per distribuire energia sulla rete ed evitare blackout.
Ahtinen afferma che la piattaforma di Confluent è fondamentale per gestire i dati in tempo reale senza le difficoltà presentate dalla gestione in proprio della piattaforma Apache Kafka. Grazie alla piattaforma di Confluent, Virta Global riesce a intervenire in modo da monitorare in tempo reale i consumi e da tagliarli qualora serva, così da preservare la stabilità della rete.
I dati in tempo reale: un tema sempre più centrale
Si parla da anni di IoT, di 5G privato, d'industria connessa, di automobili a guida autonoma. Finora sono molto poche le promesse che sono state mantenute in questi ambiti, o quantomeno le aspettative che sono state soddisfatte. Si cominciano, però, a vedere dei primi segnali che finalmente questi temi siano in dirittura d'arrivo. Un punto importante è che tutti portano con loro una grande quantità di dati in tempo reale che vanno raccolti, analizzati, catalogati, archiviati. Una mole di dati infinita, la cui gestione è proprio ciò che Confluent fa.
Non è solo un'impressione: Wähner ci ha confermato che vede sempre più sperimentazioni di questo tipo da parte dei clienti e vede nel futuro un'espansione di temi come IoT industriale e 5G privato verso aziende di piccole e medie dimensioni, fatto che renderà piattaforme come quella di Confluent una necessità non solo per le aziende di grandi dimensioni com'è (in media) ora, ma anche per realtà medio-piccole. Il messaggio che raccogliamo a Current 2025 è quindi il seguente: la rivoluzione dei dati in tempo reale sta per arrivare.
 Recensione REDMAGIC Astra Gaming Tablet: che spettacolo di tablet!
Recensione REDMAGIC Astra Gaming Tablet: che spettacolo di tablet!  Dopo un mese, e 50 foto, cosa abbiamo capito della nuova Nintendo Switch 2
Dopo un mese, e 50 foto, cosa abbiamo capito della nuova Nintendo Switch 2 Gigabyte Aero X16 Copilot+ PC: tanta potenza non solo per l'IA
Gigabyte Aero X16 Copilot+ PC: tanta potenza non solo per l'IA Ecco come Elon Musk intende controllarvi con la sua IA: la verità su Grok 4
Ecco come Elon Musk intende controllarvi con la sua IA: la verità su Grok 4 BYD rivoluziona (ancora) il settore auto: risarcimenti danni senza passare dall'assicurazione
BYD rivoluziona (ancora) il settore auto: risarcimenti danni senza passare dall'assicurazione















0 Commenti
Gli autori dei commenti, e non la redazione, sono responsabili dei contenuti da loro inseriti - infoDevi effettuare il login per poter commentare
Se non sei ancora registrato, puoi farlo attraverso questo form.
Se sei già registrato e loggato nel sito, puoi inserire il tuo commento.
Si tenga presente quanto letto nel regolamento, nel rispetto del "quieto vivere".