






Intel Cooper Lake, la terza generazione Xeon Scalable punta sull'intelligenza artificiale
di Manolo De Agostini pubblicata il 18 Giugno 2020, alle 15:01 nel canale Device
Intel ha annunciato i nuovi processori server Xeon Scalable di terza generazione, nome in codice Cooper Lake. Le nuove CPU offrono fino a 28 core e supportano il formato bfloat16 per accelerare i carichi di intelligenza artificiale.
Intel ha annunciato la disponibilità della terza generazione dei microprocessori server Xeon Scalable, nome in codice "Cooper Lake". Si tratta dei primi microprocessori con supporto integrato al formato in virgola mobile bfloat16, pensato per facilitare l'inferenza e l'allenamento di reti neurali destinate all'intelligenza artificiale direttamente sulle CPU. Tra le applicazioni che beneficeranno bfloat16 troviamo la classificazione delle immagini, il riconoscimento vocale e l'analisi di dati complessi, solo per citarne alcune.

Cooper Lake arriva in momento in cui l'uso e la comprensione dei dati sta guadagnando sempre più piede tra le aziende, aprendo nuove opportunità in settori come la finanza, la sanità, i trasporti e le telecomunicazioni. Secondo IDC il prossimo anno il 75% dei software commerciali destinati alle aziende userà l'intelligenza artificiale, mentre nel 2025 un quarto dei dati sarà creato in tempo reale, con la necessità di un'analisi rapida ed efficace.


Per questo motivo i nuovi Xeon Scalable Cooper Lake ampliano gli sforzi di Intel nel campo dell'intelligenza artificiale, integrandosi nel set di tecnologie preesistente DL Boost - introdotto con gli Xeon Scalable di seconda generazione "Cascade Lake" - che già contava sulle Vector Neural Network Instructions (VNNI). Il formato bloaf16 usa metà dei bit dell'attuale formato FP32 ma raggiunge un'accuratezza comparabile, con cambiamenti nulli o minimi al software, accelerando così l'addestramento di modelli di IA e inferenza sfruttando direttamente la CPU.

I framework principali, come TensorFlow e Pytorch, supportano bfloat16 e sono disponibili tramite il toolkit Intel AI Analytics. L'azienda statunitense offrirà inoltre ottimizzazioni per bfloat16 all'interno del toolkit OpenVINO e l'ambiente ONNX Runtime per agevolare l'inferenza.
Specifiche tecniche e modelli
Gli Intel Xeon Scalable di terza generazione sono destinati a piattaforme server con quattro o otto socket, mentre per le piattaforme con uno o due socket arriveranno nei prossimi mesi (entro l'anno) le CPU Ice Lake a 10 nanometri. Le proposte Cooper Lake sono realizzate a 14 nanometri e contano processori da 16 a 28 core (32 / 56 thread) con TDP da 150 a 250 watt. Nella seguente slide potete vedere i nomi dei vari modelli e le principali specifiche, con lo Xeon Platinum 8380H/HL a rappresentare il vertice della gamma:
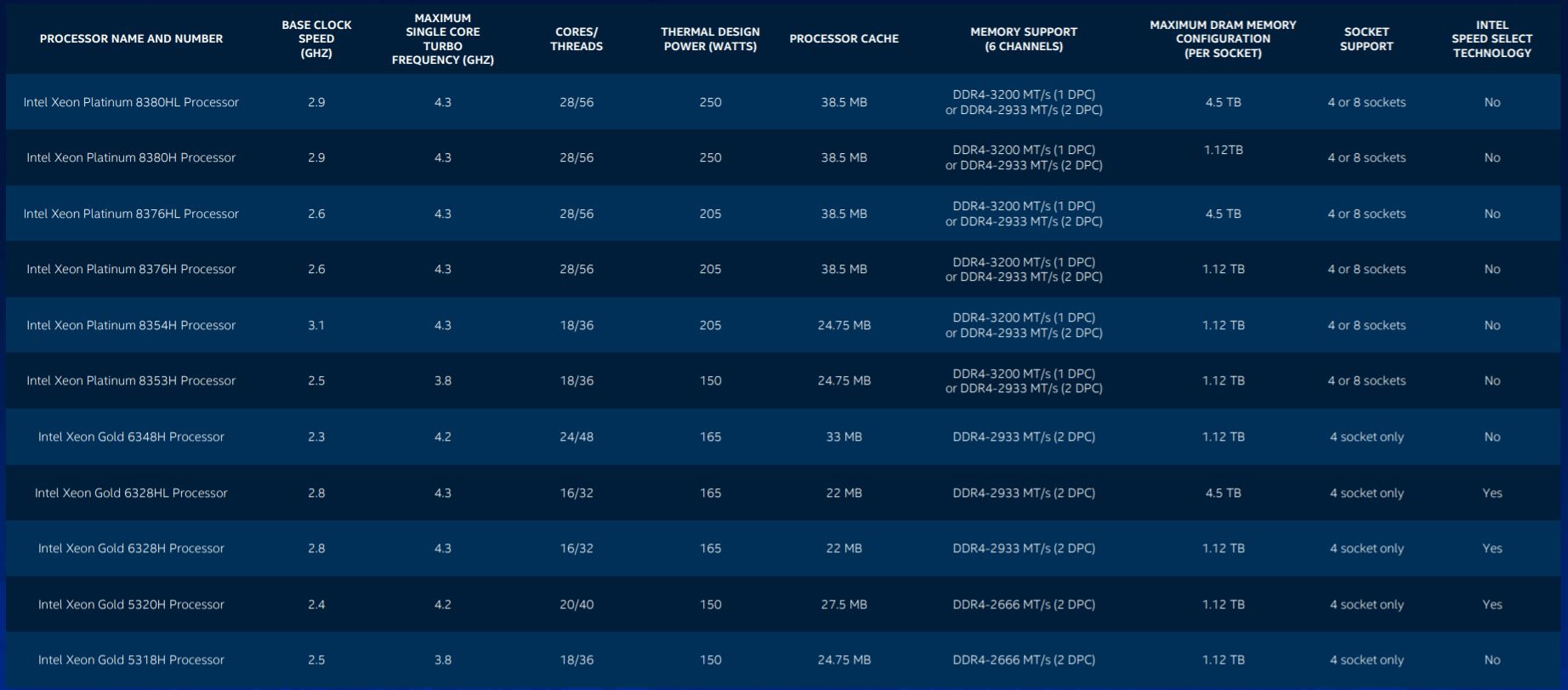
Modelli e specifiche tecniche - clicca per ingrandire
Ogni processore offre fino a 48 linee PCI Express 3.0 e sei canali di memoria con supporto DDR4 a 3200 MT/s nel caso di una DIMM per canale o 2933 MT/s con l'installazione di 2 DIMM per canale. Complessivamente ogni socket può supportare fino a 256 GB di memoria DDR4. Poiché la piattaforma supporta anche Optane Persistent Memory (OPmem), ci sono modelli di CPU che supportano fino a 4,5 TB di memoria: ogni socket supporta un modulo OPmem per canale, per un massimo di 3 TB di capacità, a cui si può aggiungere 1,5 TB di memoria DDR4. Per la comunicazione tra le CPU, Intel ha dotato i chip Cooper Lake di sei collegamenti UPI (Ultra Path Interconnect).
Secondo Intel la nuova gamma garantisce un miglioramento medio delle prestazioni del 90% con carichi di lavoro popolari, del 98% con carichi database e consente la gestione di 2,2 volte più macchine virtuali rispetto a piattaforme equivalenti quad-socket di cinque anni fa.

Caratteristiche complete della piattaforma - clicca per ingrandire
Le nuove soluzioni rappresentano le fondamenta dei più recenti server Open Compute Platform (OCP) di Facebook, e saranno adottate da moltissimi provider di servizi cloud tra cui Alibaba, Baidu e Tencent. La disponibilità generale nei sistemi OEM è prevista invece nel corso del secondo semestre di quest'anno.
"La capacità di dotarsi rapidamente di IA e analisi dati è essenziale per le aziende attuali. Rimaniamo impegnati nel migliorare l'accelerazione dell'IA e le ottimizzazioni software all'interno dei processore per datacenter e soluzioni edge, oltre a fornire hardware senza eguali per ricavare informazioni dai dati", ha affermato Lisa Spelman, vicepresidente corporate e general manager della divisione Xeon and Memory.
Non solo CPU, Intel guarda all'intero ecosistema
Insieme alle nuove CPU Xeon, Intel ha annunciato la seconda generazione di Optane Persistent Memory, parte della serie 200. Optane Persistent Memory è basata su memoria 3D XPoint e si presenta in un formato DIMM, come le classiche RAM, con la differenza che i dati rimangono stoccati all'interno della memoria, anche in assenza di energia.

L'obiettivo di Intel con questa soluzione è quello di mantenere quanti più dati vicino al socket, e in questo caso i clienti possono dotare i loro sistemi di un massimo di 4,5 TB di memoria per socket per gestire carichi come i database in memoria, analisi e virtualizzazione. I moduli sono disponibili con capacità di 128, 256 e 512 GB.
Un'altra novità riguarda gli SSD, con la disponibilità immediata di nuove soluzioni chiamate Intel SSD D7-P5500 e D7-P5600, nome in codice "Arbordale Plus". Si tratta di unità basate su memoria 3D NAND TLC a 96 layer realizzata dalla stessa Intel e con un nuovo controller a bassa latenza PCI Express 4.0 x4. Disponibili nel formato U.2 da 15 mm, questi SSD si presentano in diverse capacità e resistenze in base alla serie: i D7-P5500 offrono 1,92, 3,84 e 7,68 TB di spazio, con 1 DWPD di resistenza; le soluzioni D7-P5600 invece sono leggermente meno capienti - 1,6 TB, 3,2 e 6,4 TB - ma garantiscono una resistenza di 3 DWPD. La garanzia è di 5 anni.

Per quanto riguarda le prestazioni, Intel parla di una riduzione della latenza rispetto alla generazione precedente del 40%, mentre le prestazioni salgono del 33%. In termini più concreti, i D7-P5500 raggiungono prestazioni in lettura e scrittura sequenziale rispettivamente fino a 7000 e 4300 MB/s con blocchi di 128K. Le prestazioni casuali 4K si attestano invece a 1 milione di IOPS (lettura) e 130.0000 IOPS (scrittura). Le soluzioni P5600 sono simili, ma vedono raddoppiare le prestazioni in scrittura casuale a 260.000 IOPS. Quanto ai consumi si parla di 5W in idle e 20W di media in scrittura.
Intel ha presentato inoltre Stratix 10 NX, il suo primo FPGA ottimizzato per intelligenza artificiale, rivolto all'accelerazione di carichi di IA ad alto bandwidth e bassa latenza. Debutterà nel corso dei prossimi mesi. Secondo l'azienda statunitense queste soluzioni, disponibili nei prossimi mesi, si rivolgono in particolare a compiti come l'elaborazione del linguaggio naturale e il rilevamento delle frodi. Gli FPGA Intel Stratix 10 NX includono memoria HBM, funzionalità di rete ad alte prestazioni e nuove unità aritmetiche ottimizzate per l'intelligenza artificiale chiamate "AI Tensor Block".
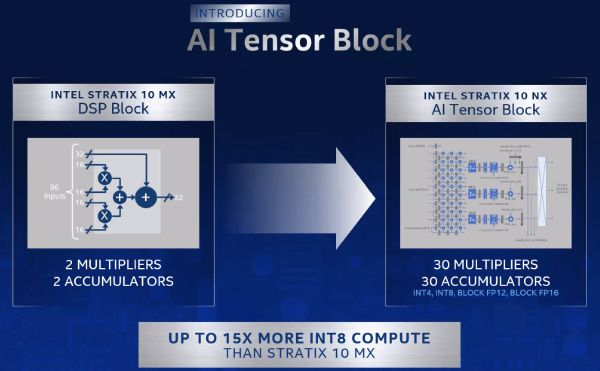
Le nuove unità, secondo Intel, garantiscono un throughput INT8 15 volte superiore rispetto ai DSP contenuti nell'attuale offerta Stratix 10 MX, restituendo benefici concreti, tanto che Microsoft ha annunciato che sfrutterà il nuovo FPGA di Intel per le proprie soluzioni di intelligenza artificiale. Intel ritiene inoltre che il nuovo Stratix 10 NX sia diverse volte più veloce di una Nvidia Volta V100 in compiti come l'analisi in tempo reale di dati video (fino a 3,8 volte) o la rilevazione di frodi (fino a 9,5 volte).

Infine, Intel ricorda che CPU, GPU, FPGA e altre soluzioni funzioneranno sfruttando una API comune chiamata OneAPI, accessibile agli sviluppatori tramite un set completo di strumenti avanzati.



 Recensione REDMAGIC Astra Gaming Tablet: che spettacolo di tablet!
Recensione REDMAGIC Astra Gaming Tablet: che spettacolo di tablet!  Dopo un mese, e 50 foto, cosa abbiamo capito della nuova Nintendo Switch 2
Dopo un mese, e 50 foto, cosa abbiamo capito della nuova Nintendo Switch 2 Gigabyte Aero X16 Copilot+ PC: tanta potenza non solo per l'IA
Gigabyte Aero X16 Copilot+ PC: tanta potenza non solo per l'IA A 179 è imbattibile: tablet 11" 2,5K, 8GB/512GB, 8580mAh, Helio G99 e anche LTE, sceso di 50
A 179 è imbattibile: tablet 11" 2,5K, 8GB/512GB, 8580mAh, Helio G99 e anche LTE, sceso di 50 Monitor da urlo in offerta su Amazon: tra OLED, 240Hz e schermi curvi c'è l'imbarazzo della scelta
Monitor da urlo in offerta su Amazon: tra OLED, 240Hz e schermi curvi c'è l'imbarazzo della scelta Il boom azionario di NVIDIA sta rendendo straricchi molti dei suoi dipendenti
Il boom azionario di NVIDIA sta rendendo straricchi molti dei suoi dipendenti















3 Commenti
Gli autori dei commenti, e non la redazione, sono responsabili dei contenuti da loro inseriti - infoPeccato che Nvidia sia già ad Ampere ora...
Al che bisognerebbe porsi la domanda: quante volte Ampere è più veloce di Volta in queste operazioni? Così ci si può rendere meglio conto della validità della soluzione Intel.
Ma anche se l'incremento fosse del doppio (+100%), Ampere non potrebbe in ogni caso impensierire Intel.
D'altra parte quella di Intel è una soluzione custom, mentre nVidia riutilizza sostanzialmente i suoi stream processor nati per la grafica, che non potranno mai essere efficienti allo stesso modo.
Devi effettuare il login per poter commentare
Se non sei ancora registrato, puoi farlo attraverso questo form.
Se sei già registrato e loggato nel sito, puoi inserire il tuo commento.
Si tenga presente quanto letto nel regolamento, nel rispetto del "quieto vivere".