






Juniper: le reti dei data center dedicati allIA sono tutta unaltra storia
di Vittorio Manti pubblicata il 03 Novembre 2023, alle 11:11 nel canale InnovazioneLa potenza di calcolo dei server basati su GPU per lintelligenza artificiale è mostruosa. Per evitare colli di bottiglia è necessario che le reti si adeguino. Juniper propone sul mercato una soluzione completa
Un incontro dedicato alla stampa organizzato da Juniper, dove abbiamo incontrato James Kelly, Product Management Senior Director, è stata l’occasione per fare il punto della situazione sull’evoluzione delle reti, in particolare quelle dedicate ai data center. Chi ha un minimo di dimestichezza con una rete di PC è abituato ad avere a che fare con cavi ethernet e switch. Con l’aumento della capacità elaborativa dei PC e, soprattutto, dei server, sono parallelamente aumentate le richieste delle reti, in termini di prestazioni e non solo. Oggi si “viaggia” su Ethernet, nei data center, fino a 400 Gbps, e si sta diffondendo la fibra ottica anche per connettere server presenti in un unico data center. Parallelamente, si sta sviluppando sempre di più il concetto di SDN, Software-Defined Networking, che crea uno strato di astrazione software per la gestione della rete, che ottimizza il flusso di dati e rende più semplice disegnare e tenere sotto controllo l’architettura della rete. Semplificando al massimo, però, in una rete tradizionale, possiamo immaginare che da ogni dispositivo parta un cavo di rete, che si collega a uno switch e che, a loro volta, ogni switch di una determinata rete sia collegato, direttamente o indirettamente, a tutti gli altri switch. Ci penserà poi “l’intelligenza” presente all’interno dell’hardware stesso, o la piattaforma di gestione SDN a instradare il traffico e a permettere a ogni risorsa di “vedere” le altre.

L’IA rende obsolete le reti tradizionali
Già questo tipo di architettura può diventare particolarmente complessa e, in organizzazioni di grandi dimensioni, richiede competenze specifiche e specializzate per essere gestita al meglio. Con l’evoluzione dell’IA, in particolare con la diffusione dei Large Language Models, che sono alla base dei modelli di IA generativa, la complessità è cresciuta di alcuni ordini di grandezza e cambia il paradigma stesso di come sono strutturate le reti.
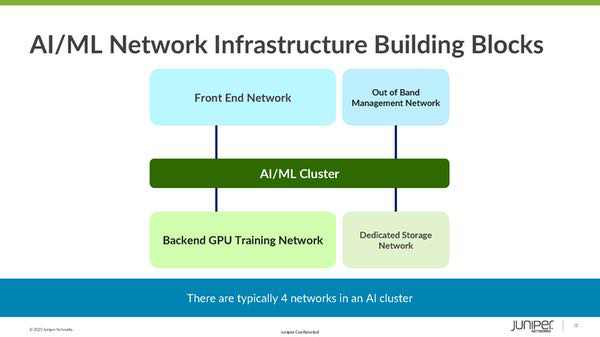
Per comprendere la portata di questo cambiamento, dobbiamo aggiungere alcuni tasselli. Va compreso come è progettata, a livello concettuale, l’infrastruttura di rete su cui si appoggia l’architettura di un sistema dedicato all’IA. Le due fasi, training e inferenza, hanno richieste, in termini di capacità di elaborazione e di accesso alla rete, molto diverse. I server dedicati all’inferenza con cui deve interagire l’utente finale devono essere accessibili attraverso Internet o comunque da una rete distribuita, ma le richieste in termini di capacità elaborativa sono limitate e normalmente è sufficiente un’unica GPU. Questa rete è chiamata Front End Network e non ha requisiti molto diversi da una rete tradizionale. I server dedicati al training, invece, devono essere accessibili solo dagli sviluppatori e possono quindi essere posizionati in una rete “chiusa”, denominata backend, dove però le richieste in termini di prestazioni della rete sono “mostruose” e, di fatto, incompatibili con un’architettura standard, per quanto complessa. A questo va aggiunto che va in ogni caso creato un collegamento fra i server di training e quelli di inferenza, anzi a volte all’interno dello stesso server alcune GPU sono dedicate al training e altre all’inferenza. In questo tipo di architettura ci sono poi altre due componenti da tenere in considerazione: l’out of band per il management della rete e la rete dedicata allo storage. Parliamo solo di GPU perché uno dei tasselli fondamentali, se non il più importante, di tutto questo discorso è che oggi NVIDIA la fa da padrone nel mondo dell’IA. Nella stragrande maggioranza dei casi l’elaborazione viene fatta su GPU NVIDIA, e la stessa azienda fornisce sul mercato server basati su GPU.
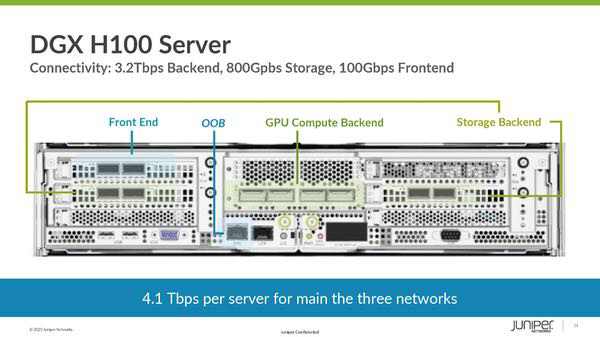
Vengono utilizzati anche diverse migliaia di questi server in parallelo nei data center dedicati all’IA più grandi, con forti necessità in termini di networking e quindi, per evitare che la rete diventi un collo di bottiglia, è necessaria un’architettura che garantisca velocità di connessione elevatissima e, contemporaneamente, bassissima latenza. Va aggiunto che questi server nascono per essere integrati in reti ad altissime prestazioni. È sufficiente guardare con attenzione il retro di un server per comprendere quanto la componente networking sia essenziale. Un server come l’NVIDIA DGX H100 monta “on-board” connettività che permette di raggiungere 3,2 Tbps (Terabit al secondo) sulla rete backend, 800 Gbps per lo storage e 100 Gbps per il frontend, parliamo quindi di 4,1 Tbps di banda complessiva per ogni singolo server. Una rete con architettura tradizionale non sarebbe in grado di gestire in modo efficace cluster di migliaia di server con una potenzialità di banda così elevata.
Juniper ha la soluzione per le reti dedicate all’IA

È qui che entra in gioco Juniper. James Kelly, nell'incontro dedicato alla stampa, ha sottolineato come Juniper sia una delle poche aziende al mondo a proporre sul mercato una piattaforma completa per la gestione di reti complesse come quelle necessarie per i carichi di lavoro dell’IA. Non è l’unica a farlo, e uno dei concorrenti è proprio NVIDIA, che propone una soluzione proprietaria chiamata InfiniBand. Il vantaggio offerto da Juniper è quello di utilizzare standard di mercato, anzi di proporre una piattaforma di networking intend-based multivendor. Grazie alla sua vasta gamma di prodotti, Juniper consente alle aziende di integrare dispositivi di diversi vendor all'interno della stessa infrastruttura, semplificando la gestione e riducendo i costi operativi. In particolare, la piattaforma di Juniper consente di monitorare e gestire l'intera rete attraverso un'unica console, indipendentemente dal tipo di dispositivo utilizzato. Inoltre, è possibile automatizzare la distribuzione dei servizi in modo rapido ed efficiente, semplificando il provisioning e riducendo gli errori umani. Grazie a queste soluzioni innovative, Juniper è in grado di offrire ai propri clienti una maggiore agilità e flessibilità nella gestione delle reti aziendali, garantendo al contempo una maggiore sicurezza e affidabilità del sistema.
In questo contesto, Juniper ha sviluppato un’architettura di rete “Leaf-Spine” che garantisce le prestazioni, la robustezza e la resilienza necessarie in un contesto complesso come quello delle reti dedicate ai data center specializzati nell’IA. Gli switch spine fungono da dorsale centrale della rete. Tutti gli switch leaf sono connessi a ogni switch spine. Questo assicura che il traffico tra qualsiasi coppia di switch leaf attraversi al massimo due switch - uno leaf e uno spine. Questo riduce la latenza e migliora la velocità di trasmissione dei dati. Gli switch leaf sono connessi a server, dispositivi di storage, o altri switch leaf. In un data center, ogni switch leaf fornisce l'accesso ai server attraverso porte ad alta velocità. Il fatto che ogni switch leaf sia collegato a tutti gli switch spine garantisce prestazioni molto elevate ma, allo stesso tempo, rende molto più complessa l’infrastruttura. Non è quindi sufficiente offrire sul mercato prodotti come le serie QFX5K, pensati per svolgere il ruolo di leaf, e le serie PTX10K, adatti invece a fungere da spine. Juniper mette a disposizione una soluzione end-to-end, che vende nella piattaforma software Juniper apstra il collante per gestire, in ottica SDN, tutte le componenti della rete.
Questo tipo di architetture, come dicevamo, si rendono necessarie per gestire infrastrutture di una complessità così elevata con cui la maggior parte delle aziende non dovrà mai confrontarsi. È però importante sapere quali sono le sfide con cui si stanno confrontando le aziende specializzate in IA e quelle dedicate al networking, come Juniper, perché l’esperienza fatta in questi contesti potrà poi essere travasata anche nelle reti utilizzate dalle aziende con minori richieste in termini di performance. È un po’ come guardare un gran premio di Formula 1: non guideremo mai la Ferrari di Leclerc, ma le tecnologie implementate in F1, prima o poi, arriveranno anche nelle auto che guidiamo tutti i giorni.



 Recensione REDMAGIC Astra Gaming Tablet: che spettacolo di tablet!
Recensione REDMAGIC Astra Gaming Tablet: che spettacolo di tablet!  Dopo un mese, e 50 foto, cosa abbiamo capito della nuova Nintendo Switch 2
Dopo un mese, e 50 foto, cosa abbiamo capito della nuova Nintendo Switch 2 Gigabyte Aero X16 Copilot+ PC: tanta potenza non solo per l'IA
Gigabyte Aero X16 Copilot+ PC: tanta potenza non solo per l'IA Prime Day finito, non le offerte: un weekend di sorprese e prezzi super anche sui grandi marchi (Apple, DJI, Lenovo e altri)
Prime Day finito, non le offerte: un weekend di sorprese e prezzi super anche sui grandi marchi (Apple, DJI, Lenovo e altri) YouTube manda in pensione la pagina Tendenze: addio dopo 10 anni
YouTube manda in pensione la pagina Tendenze: addio dopo 10 anni Scopa elettrica Chebio, gran ritorno a soli 109: ha rivoluzionato il mercato, è ottima e con accessori
Scopa elettrica Chebio, gran ritorno a soli 109: ha rivoluzionato il mercato, è ottima e con accessori















0 Commenti
Gli autori dei commenti, e non la redazione, sono responsabili dei contenuti da loro inseriti - infoDevi effettuare il login per poter commentare
Se non sei ancora registrato, puoi farlo attraverso questo form.
Se sei già registrato e loggato nel sito, puoi inserire il tuo commento.
Si tenga presente quanto letto nel regolamento, nel rispetto del "quieto vivere".