






AWS re:Invent 2023: la visione di AWS sul presente e il futuro dellintelligenza artificiale
di Vittorio Manti pubblicato il 06 Dicembre 2023 nel canale Cloud
Si chiude unedizione di AWS re:Invent focalizzata sullintelligenza artificiale. Cè stato lannuncio di Amazon Q, lassistente in stile ChatGPT di AWS, ma anche molto di più, perché la visione di AWS per lIA va oltre lintelligenza artificiale generativa
To predict the future, observe the present. Per predire il futuro, osserva il presente. Si chiude così l’ultimo keynote di AWS re:Invent 2023, condotto come sempre magistralmente da Werner Vogels, CTO di Amazon.com. Noi seguiremo questo consiglio per cercare di raccontare quello che abbiamo visto a Las Vegas, durante una settimana che non ha riservato particolari colpi di scena, ma ci ha sicuramente lasciato una fotografia molto nitida e fedele del presente di AWS. Seguendo il consiglio di Werner Vogels l’analisi di questo presente ci mette a disposizione diversi strumenti per predire quello che potrà essere il futuro, non solo di AWS ma di tutto il settore del cloud e, di conseguenza, anche dell’IT in generale e dell’intelligenza artificiale in particolare.

Dire che non ci sono stati colpi di scena non significa che gli annunci fatti al re:Invent 2023 non siano significativi, anzi. C’era molta attesa riguardo la posizione di AWS nei confronti dell’intelligenza artificiale generativa e quindi non è stata una sorpresa che questo sia stato l’argomento principale di tutto l’evento. Se dobbiamo scegliere un fotogramma che sintetizzi re:Invent 2023 non selezioniamo quello dedicato ad Amazon Q, l’assistente virtuale da molti paragonato a ChatGPT, bensì la foto di Adam Selipsky, CEO di AWS, con alle spalle una slide riassuntiva dell’intero “generative AI stack”. Riteniamo sia stata una precisa scelta comunicativa quella di non dare troppa enfasi all’applicazione che la maggior parte degli utenti potrà presto utilizzare, perché per AWS l’assistente è solo la punta dell’iceberg di un ecosistema molto più ampio, pensato primariamente per chi sviluppa applicazioni e soluzioni che solo in seconda battuta arriveranno nelle mani degli utilizzatori finali.

Una domanda interessante da porsi è: come si confronta Amazon Q con gli assistenti più “famosi” come ChatGPT e Microsoft Copilot? Nel rispondere a questa domanda vedremo che si riesce anche a far emergere il diverso approccio, in generale sull’intelligenza artificiale, di realtà come OpenAI, Microsoft e AWS. Per rispondere a questa domanda però non possiamo partire dalla “fine”, da Amazon Q, ma dobbiamo fare almeno due passi indietro e analizzare l’intero “generative AI stack” descritto da AWS sul palco del Venetian di Las Vegas.
Possiamo suddividere lo stack di AWS per l’intelligenza artificiale generativa su tre livelli:
- Infrastruttura per addestramento e inferenza dei foundation models
- Strumenti per sviluppare servizi e applicazioni con large language models e altri foundation models
- Applicazioni che si appoggiano sui foundation models

L’infrastruttura: il punto di partenza per la visione dell’IA di AWS
Parlando di infrastruttura è utile citare un concetto alla base della filosofia stessa di AWS. Visto il ruolo che ricopre Werner Vogels, quello di CTO di Amazon.com, non di AWS, non stupisce che durante il suo keynote abbia fatto diversi riferimenti a come i servizi offerti da AWS permettano al più importante sito di e-commerce di servire in modo sempre più efficace centinaia di milioni di utenti in tutto il mondo. Vogels è sicuramente un personaggio molto eccentrico, l’unico a presentarsi sul palco in t-shirt, e questa sua eccentricità, unita a un livello di competenze davvero unico al mondo, gli permette di parlare senza peli sulla lingua. Un concetto al centro della sua visione complessiva è la frugalità, vista come la capacità di realizzare qualsiasi cosa, volendo non solo in campo tecnologico, facendo sempre attenzione che i costi associati siano sostenibili.

Questo approccio ha portato Vogels a definire le sette leggi del “Frugal Architect” (per chi fosse interessato sono enunciate su https://thefrugalarchitect.com/). Diventa sempre più indispensabile seguire queste leggi nell’era dell’intelligenza artificiale perché le richieste in termini di capacità elaborativa e spazio di archiviazione sono aumentate in modo esponenziale e quindi, ancora più di prima, è fondamentale saperle gestire in modo efficiente, per evitare che i costi associati diventino incontrollabili. Visto il modello di AWS, che “espone” ai clienti quanto i servizi costano ad AWS stessa, spendere meno è una buona approssimazione per valutare la capacità di sviluppare e sfruttare in modo efficiente le risorse, cosa che ha anche l’effetto benefico di incidere meno da un punto di vista ambientale. È quindi molto consigliabile, per sfruttare al meglio i servizi infrastrutturali offerti da AWS, seguire la filosofia “frugale” ed entrare in sintonia con il modo in cui AWS stessa opera.
È in questo contesto che Adam Selipsky ha fatto due diversi importanti annunci durante il suo keynote: Graviton4 e il rafforzamento della partnership con NVIDIA. I dettagli tecnici legati a questi annunci potete trovarli qui, mentre in questo contesto vogliamo analizzare la valenza di queste novità nello stack di IA generativa di AWS. Graviton è la serie di processori su architettura ARM sviluppati direttamente da AWS, che poi li offre ai clienti in istanze EC2 con diverse configurazioni di CPU, memoria, storage e rete.

AWS afferma che, a parità di capacità elaborativa, le macchine con Graviton hanno costi inferiori rispetto alle altre soluzioni offerte nella piattaforma AWS. Graviton4 offre poi performance superiori del 30% rispetto alla generazione precedente e il lancio è stato accompagnato da Trainium2, una soluzione specifica per l’addestramento di modelli di intelligenza artificiale. In questo ambito, però, NVIDIA è lo standard di mercato e, in sintonia con la strategia di proporre sempre soluzioni alternative, il rafforzamento della partnership porta AWS a essere il primo cloud provider a offrire le nuove soluzioni NVIDIA GH200 Grace Hopper Superchip, a tutti gli effetti la più potente piattaforma hardware attualmente sul mercato per l’addestramento dei foundation models.

Arrivati a questo punto non possiamo ancora rispondere alla domanda sulle differenze fra Amazon Q, ChatGPT e Copilot, perché siamo ancora lontani dallo strato applicativo dello stack, ma possiamo già cogliere i primi indizi sull’approccio generale di AWS all’intelligenza artificiale generativa. Così come Graviton si affianca ad altri processori per le applicazioni general purpose e Trainium e le GPU NVIDIA vengono proposti per elaborazioni specifiche in campo IA, AWS mette a disposizione queste risorse per chi vuole “partire da zero” e sviluppare ogni aspetto di una soluzione di intelligenza artificiale, non solo legata all’IA generativa. Nello strato infrastrutturale dello stack AWS inserisce anche SageMaker, piattaforma lanciata nell'ormai lontano 2017 che permette di creare e sviluppare modelli di machine learning con applicazioni diverse rispetto all'IA generativa, ma comunque attuali, in funzione del fatto che le due implementazioni dell'IA sono complementari e non sostitutive una dell'altra. AWS non è l’unico cloud provider a offrire questo strato dello stack, che è pensato primariamente per sviluppatori che vogliono costruire i propri modelli e piattaforme da offrire, idealmente, sul mercato, mentre è probabile che le aziende, anche quelle più grandi, andranno a sfruttare anche gli altri strati dello stack, se non direttamente sfruttare i servizi degli sviluppatori. L’indizio che cogliamo analizzando questo strato è che AWS vuole servire l’intero mercato, con soluzioni flessibili e che poi sono compatibili con gli strati superiori dello stack. L’altro aspetto che emerge è che per AWS, giustamente ci sentiamo di aggiungere noi, IA non significa solo generativa, ma comprende anche altre componenti, come il machine learning, che continuano ad avere un ruolo fondamentale.
Amazon Bedrock: lo step intermedio nella creazione di applicazioni di IA generativa
Costruire da zero un foundation model è un’operazione molto onerosa e complessa, servono competenze molto specifiche e, in ultima analisi, in molti casi non è necessario. Questa considerazione viene confermata dal fatto che sono nate diverse realtà dedicate alla creazione e gestione di foundation models, che poi sono utilizzati per lo sviluppo di applicazioni specifiche. Amazon Bedrock si posiziona nello stack per l’intelligenza artificiale generativa di AWS nello strato intermedio degli strumenti offerti a chi sviluppa applicazioni e servizi.

Amazon Bedrock si pone l’obiettivo di mettere a disposizione dei propri clienti un servizio gestito che permette di accedere tramite API a una selezione di foundation models. Bedrock è il cuore del secondo strato dello stack di IA generativa e, insieme ai modelli, mette a disposizione degli utenti AWS una serie di strumenti per sviluppare applicazioni anche su larga scala. I principali modelli disponibili tramite Bedrock sono, fra gli altri: Amazon Titan (sviluppato direttamente da AWS), Claude di Anthropic, Llama 2 di Meta, Command ed Embed di Cohere. Analizzando l’elenco di modelli disponibili è impossibile non fare delle considerazioni sugli schieramenti che si stanno disponendo sul mercato dell’IA. Da un lato c’è AWS, con modelli proprietari e l’investimento di 4 miliardi di dollari fatto in Anthropic. Dall’altro c’è Microsoft con l’investimento di oltre 10 miliardi di dollari in OpenAI e nel mezzo realtà specializzate, come Cohere, che sono trasversali a entrambi i contendenti, visto che oltre a essere presenti in Bedrock offrono i loro modelli a Oracle, che nel frattempo si è schierata nel campo di Microsoft. Questi schieramenti sembrano anche seguire le posizioni più “filosofiche” legate allo sviluppo dell’IA. Va ricordato che il team di Anthropic è composto da un gruppo fuoriuscito da OpenAI, perché in contrasto con l’approccio “spregiudicato” nella gestione dell’IA, quello che sembra essere stato il motivo per cui il CEO di OpenAI era stato inizialmente allontanato. Anche sul palco di re:Invent il CEO di Anthropic ha ribadito la missione dell’azienda di voler sviluppare soluzioni di IA generativa che tengano in considerazione i rischi collegati e quindi l’investimento fatto da AWS in Anthropic sembra allineare l’azienda guidata da Adam Selipsky a questa visione più conservativa.

Visione che vede una concreta applicazione nel modello di sviluppo di Bedrock e, vedremo successivamente, anche di Amazon Q. È andato più nel dettaglio Swami Sivasubramanian, VP, Database, Analytics and ML di AWS, nel keynote di mercoledì descrivendo un modello di sviluppo su cui sembrano convergere tutti gli attori del mercato. Il presupposto è che per ottenere dei risultati rilevanti dall’intelligenza artificiale generativa non ci si può basare solo su modelli generici, ma è indispensabile ancorare i risultati a fonti di dati specifiche, quindi proprietarie. Questo però crea un problema di salvaguardia dei dati aziendali, perché se il modello generale viene addestrato sui dati proprietari diventa poi impossibile limitare l’accesso a quei dati da terze parti esterne all’organizzazione. Utilizzando Bedrock, AWS garantisce che il modello generale, qualsiasi modello venga utilizzato, non viene addestrato con i dati proprietari, ma che questi dati vengono utilizzati solo all’interno del “dominio” di ogni specifico cliente per generare risultati più rilevanti. Ogni cliente, che usa i propri dati, otterrà quindi dei risultati diversi e rilevanti per la propria organizzazione, con la garanzia che quei dati non usciranno mai dal dominio aziendale.

Un altro aspetto significativo, nello sviluppo di applicazioni di intelligenza artificiale generativa che siano in grado di generare risultati rilevanti, è legato a come i modelli interagiscono con varie tipologie di dati che hanno la caratteristica comune di essere dati non strutturati. Testi, immagini, audio e video non sono interpretati “direttamente” dai modelli, ma attraverso dei “vector embeddings” ossia una rappresentazione numerica dei dati stessi. La creazione dei “vector embeddings” avviene utilizzando degli algoritmi matematici, che generano dei vettori con un numero fisso di dimensioni, con un range però molto ampio che va da alcune decine fino a decine di migliaia, in funzione della complessità del dato che devono rappresentare (banalmente il vettore che rappresenta un testo avrà un numero di dimensioni sensibilmente inferiore a quello di un video). Se un singolo vector embedding può essere considerato l’equivalente di un record di un database tradizionale pensato per gestire dati strutturati, dobbiamo trovare uno strumento adatto a gestire dati non strutturati. Durante re:Invent 2023 abbiamo avuto l’occasione di discutere dell’argomento con Boris Bialek di MongoDB, un database nato proprio per gestire dati non strutturati. MongoDB è oggi diventato una piattaforma completa di gestione dei dati sul cloud ed è integrato in AWS e in altri hyperscaler, così da mettere a disposizione degli utenti servizi per la distribuzione e la mobilità dei dati fra i vari cloud provider. C’è comunque una differenza fra il formato BSON, un parente stretto di JSON utilizzato da MongoDB per creare archivi di dati non strutturati, e i vector embeddings. La soluzione offerta da MongoDB è Atlas Vector Search, che permette di integrare database BSON e vettori in un’unica piattaforma gestita con un’unica interfaccia e che è pensata per interagire con gli LLM. Un altro tassello importante da prendere in considerazione è come differisce una ricerca in un database tradizionale e una “vector search”. In un DB tradizionale c’è una corrispondenza univoca a precisa fra la query effettuata sui dati e il risultato ottenuto, mentre in un vector databse è possibile trovare dei risultati che siano simili al significato semantico o contestuale di un dato di esempio.
Per capire in concreto questa differenza Boris Bialek ci ha mostrato una demo molto significativa. All’interno di un sito di e-commerce è stata effettuata una ricerca per “tan purse” (borsa beige) e basandosi su un database tradizionale venivano mostrati molti risultati, non tutti rilevanti, nella maggior parte dei casi prodotti beige, ma non solo borse. Attivando la ricerca vettoriale, invece, venivano mostrate esclusivamente borse beige, perché il sistema aveva associato un “significato” univoco alla coppia di parole "tan" e "purse" ed era stato in grado di associare quel significato ai prodotti corrispondenti.
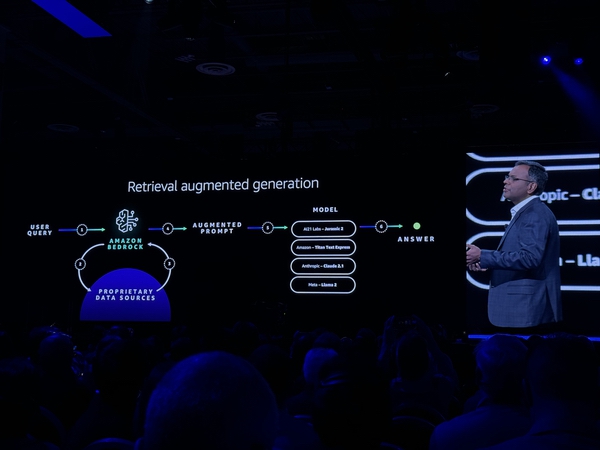
La novità annunciata a Las Vegas è che a breve MongoDB sarà fra i vector database integrati in Amazon Bedrock. Questa è una novità significativa perché vuol dire che una piattaforma come MongoDB, come le altre integrate in Bedrock, potrà diventare il “centro di controllo” e fare da collante fra il patrimonio di dati aziendali e i modelli di intelligenza artificiale generativa. In funzione del fatto che AWS considera l’intero stack intrinsecamente sicuro e, come dicevamo prima, mantiene all’interno del “dominio” aziendale i dati proprietari, grazie a questa integrazione in Bedrock, una soluzione come MongoDB può diventare centrale nel concetto di “retrieval augmented generation”, ossia ottenere dei risultati rilevanti e contestualizzati da richieste fatte attraverso un modello di IA generativa.
Quello che emerge in modo incontrovertibile, ascoltando MongoDB o AWS, è la centralità dei dati o, per meglio dire, della gestione dei dati in qualsiasi scenario legato all’intelligenza artificiale. Se è vero che per ottenere dei risultati rilevanti è necessario creare un legame fra IA generalista e dati aziendali, per i modelli è e sarà sempre più necessario appoggiarsi a degli specialisti; se questi dati non sono strutturati e gestiti in modo efficace, qualsiasi, qualsiasi considerazione sulla rilevanza dei risultati decade. Ci stiamo avvicinando al momento in cui potremo dare una risposta alla domanda iniziale sul confronto fra Amazon Q e gli altri assistenti, ma già adesso possiamo affermare che, anche nel caso di Amazon Q, è indispensabile che i dati aziendali siano strutturati e gestiti in modo efficace.
Amazon Q è davvero il punto di arrivo per le applicazioni di IA generativa?
Non vogliamo confondere le idee rispondendo a una domanda con un’altra domanda, ma guardando allo stato attuale di Amazon Q, è altrettanto vero che non è possibile dare una risposta definitiva sul confronto fra Amazon Q e ChatGPT. Lo sviluppo di ChatGPT è molto più avanti, rendendo un confronto diretto praticamente impossibile. Va poi chiaramente aggiunto che la finalità stessa di ChatGPT è diversa, essendo un servizio generalista e “aperto”. Con ChatGPT 4 è possibile adesso fare il fine tuning su documenti specifici, ma sicuramente, a livello aziendale, ci sono molti temi legati alla riservatezza dei dati che non ne premettono un uso diretto. Dal punto di vista della salvaguardia dei dati è più rilevante fare un confronto con Copilot for Microsoft 365, come abbiamo scritto qui, ma il grounding sui dati aziendali è strettamente legato alla piattaforma Microsoft e, in questa fase, alle aziende che sottoscrivono delle licenze Enterprise.

Amazon Q è un’applicazione di intelligenza artificiale generativa sviluppata direttamente da AWS e quindi, in questa fase, rappresenta il terzo livello dello stack. Maggiori informazioni su Amazon Q le trovate qui. La promessa di AWS con Amazon Q è di potersi interfacciare con diverse fonti di dati, riuscendo al contempo a gestire i privilegi di accesso di ogni singolo utente, mostrando quindi risultati che sono legati solo ai dati a cui l’utente che sta interrogando il sistema può effettivamente accedere. Rispetto a ChatGPT o Copilot però Amazon Q non è una soluzione già disponibile e pronta all’uso, indipendentemente dal fatto che è in fase di Preview. Amazon Q è un servizio attivabile all’interno della piattaforma di AWS che va configurato, per quanto la procedura sia semplice. Solo dopo aver collegato le fonti di dati viene generata una web app a cui gli utenti potranno accedere autonomamente.
La struttura di funzionamento di Amazon Q e l’intero stack per l’IA generativa di AWS sono una testimonianza chiara di quale sia l’approccio del primo hyperscaler al mondo. AWS non offre applicazioni preconfezionate all’utente finale, ma una piattaforma articolata che può essere adattata a qualsiasi esigenza legata all’intelligenza artificiale, generativa e non. Chiaramente questa flessibilità si accompagna alla necessità di avere le competenze per sviluppare applicazioni sulla piattaforma. AWS è nata come fornitore di servizi infrastrutturali sul cloud, il primo servizio di successo è stato S3, e si è evoluta nel creare una piattaforma che offre innumerevoli servizi. Nasce quindi come fornitore di servizi IaaS (Infrastructure-as-a-Service) e si è poi evoluta nel proporre servizi in modalità PaaS (Platform-as-a-Service). Con Amazon Q si sfiora la modalità SaaS (Software-as-a-Service) in modo coerente con quello che ci aveva detto Francessca Vasquez l’anno scorso. In un anno il mondo della tecnologia è cambiato: dopo il lancio di ChatGPT, l’intelligenza artificiale è al centro di una vera e propria rivoluzione. AWS ha presentato la sua formula per gestire questo delicato momento di passaggio e considerando che siamo solo in una fase iniziale di questo cambiamento, potremo valutare solo in futuro se la formula si rivelerà vincente.
 Polestar 3 Performance, test drive: comodità e potenza possono convivere
Polestar 3 Performance, test drive: comodità e potenza possono convivere Qualcomm Snapdragon X2 Elite: l'architettura del SoC per i notebook del 2026
Qualcomm Snapdragon X2 Elite: l'architettura del SoC per i notebook del 2026 Recensione DJI Mini 5 Pro: il drone C0 ultra-leggero con sensore da 1 pollice
Recensione DJI Mini 5 Pro: il drone C0 ultra-leggero con sensore da 1 pollice Amazon Leo Ultra: l'antenna per navigare fino a 1 Gbps grazie alla connettività satellitare
Amazon Leo Ultra: l'antenna per navigare fino a 1 Gbps grazie alla connettività satellitare Thales Alenia Space: siglati i contratti per la costruzione del lander lunare Argonaut di ESA
Thales Alenia Space: siglati i contratti per la costruzione del lander lunare Argonaut di ESA















0 Commenti
Gli autori dei commenti, e non la redazione, sono responsabili dei contenuti da loro inseriti - infoDevi effettuare il login per poter commentare
Se non sei ancora registrato, puoi farlo attraverso questo form.
Se sei già registrato e loggato nel sito, puoi inserire il tuo commento.
Si tenga presente quanto letto nel regolamento, nel rispetto del "quieto vivere".